SpringBoot2
SpringBoot2
三刷总算想起做点笔记,这点很重要 语雀官方笔记 重点看源码讲解的视频、Web开发这一章
每导入一个 starter 改写哪些配置直接看官网!!!有些什么配置一目了然!
还有自动化配置文档,这个倒idea双shift找properties也行
看到了P25,由于求职形势逼迫。搁浅... 做项目快速上手能干,往后再回头了
补充面试常问:SpringBoot:
- 自动装载
怎么实现starter(看我SpringBoot代码的Demo,要知道流程)- bean的生命周期

上面图片的所有基础原生开发,都有另一套方案用响应式替代。支持两种模式开发 @ConditionalOnWebApplication(type = Type.SERVLET) Spring5 除现在用的原生Servlet外多了一套解决方案:响应式开发!!于是SpringBoot出2跟着整 第一季就是掌握整个Sevlet技术栈
第二季响应式还没出,坐等,底层依赖reactor、Netty-reactor 异步非阻塞的方式占用少量资源处理大量并发SpringBoot 2.0 基于 Spring 5 最大的变化就是引入了 React(响应式编程)-> Web Flux(可以非常容易的创建出高性能、高并发的 Web 应用)
例如:Gateway 的跨域 Filter 网关,CorsWebFilter 它是属于 Webflux
------基础入门------
一、Spring与SpringBoot
1.Spring能做什么
1.1.Spring的能力
Spring 生态很庞大:细数自己用过的。微观是Spring框架 宏观是一套解决方案生态圈!
- Spring Boot
- Spring Cloud (Spring Cloud Alibaba)
- Spring Framework (Features:Integration->Caching)
- Spring Data (JDBC、JPA、Redis implementation for Spring 3.1 cache abstraction)
- Spring Session (Data Redis)
- Spring AMQP (RabbitMQ)
1.2.Spring5重大升级
1.2.1.响应式编程

1.2.2.内部源码设计
由于Spring5重大升级 内部源码设计基于Java8的一些新特性,如:接口默认实现。重新设计源码架构!
Spring5基于jdk8,jdk8特性多了接口的默认实现。带来的变化: 问题场景:要是以前底层还需搞个适配器模式(适配器实现接口,实现类继承适配器重写 -> 避免必须实现一些不需要的方法) 处理:接口都统一给一个默认实现,就不需要适配器类了!!!
2.为什么用SpringBoot
举例如要组装成一台电脑集合上面的技术 配置地狱,而这就是SpringBoot的存在意义它是一个高层框架底层是Spring为了整合Spring整个技术栈 专心于业务逻辑(框架的框架),免于那么多繁琐的配置。不用自己手动组装电脑了,直接买个品牌机!无需掌握各种组装技术!!!
2.1.SpringBoot优点
以下摘自官网,Title Link 可入 ~ 可以细看心里解读解读
Spring Boot makes it easy to create stand-alone, production-grade Spring based Applications that you can "just run". 能快速创建出生产级别的Spring应用
Create stand-alone Spring applications
- 创建独立Spring应用
Embed Tomcat, Jetty or Undertow directly (no need to deploy WAR files)
- 内嵌web服务器
Provide opinionated 'starter' dependencies to simplify your build configuration
- 自动starter依赖,简化构建配置**(防止各jar包冲突)**
Automatically configure Spring and 3rd party libraries whenever possible
- 自动配置Spring以及第三方功能**(激动人心的特性,对于固定化配置全给你配好 例如mysql redis只要告诉地址之类的而不需要再告诉它什么东西怎么做例如配置数据源。)**
Provide production-ready features such as metrics, health checks, and externalized configuration
- 提供生产级别的监控、健康检查及外部化配置**(针对运维来说巴适,例如写个配置文件无需回头改代码再发布)**
Absolutely no code generation and no requirement for XML configuration
- 无代码生成、无需编写XML**(自动配置)**
SpringBoot是整合Spring技术栈的一站式框架
SpringBoot是简化Spring技术栈的快速开发脚手架
2.2.时代背景
陌生的两个东西:听视频老师讲讲
- Spring Cloud Data Flow(那张经典图三板斧中的,连接一切)
- 云原生(同运维有很大关系!) Serverless(区别直接买一台几核几G的服务造成浪费,这个可以做到用多少占多少。虽然现在不理解但是先码上)
二、自动配置
两大优秀特性:依赖管理、自动配置
1.依赖管理
1.1.版本仲裁
1)依赖管理
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.4.RELEASE</version>
</parent>
2)他的父项目:几乎声明了所有开发中常用的依赖的版本号,自动版本仲裁机制
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>2.3.4.RELEASE</version>
</parent>
-------------------------------------------------------
1、引入依赖默认都可以不写版本
2、引入非版本仲裁的jar,要写版本号。
-------------------------------------------------------
3)舍弃父依赖的版本控制,自定义版本
查看spring-boot-dependencies里面规定当前依赖的版本 用的 key。
在当前项目里面重写配置
<properties>
<mysql.version>5.1.43</mysql.version>
</properties>1.2.starter场景启动器
重点第五点,这个starter又会带出
spring-boot-autoconfigure具体看自动配置
1、见到很多 spring-boot-starter-* : *就某种场景 All official starters follow a similar naming pattern;
2、只要引入starter,这个场景的所有常规需要的依赖我们都自动引入
3、SpringBoot所有支持的场景
https://docs.spring.io/spring-boot/docs/current/reference/html/using-spring-boot.html#using-boot-starter
4、见到的 *-spring-boot-starter: 第三方为我们提供的简化开发的场景启动器。
5、所有场景启动器最底层的依赖 每个 official starts 下的第一个 dependency 就是下面这个 ↓
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
<version>2.3.4.RELEASE</version>
<scope>compile</scope>
</dependency>2.自动配置(重要)
springboot METAINFO-spring.factoies 是 SPI 机制!!! 写这里面的类会暴露给 EnableAutoConfiguration注解
@SpringBootApplication
等同于
@SpringBootConfiguration #配置类
@EnableAutoConfiguration #按需自动配置 **核心**
1)@AutoConfigurationPackage
@Import(AutoConfigurationPackages.Registrar.class) //扫描的是配置类,区分@ComponentScan
2)@Import(AutoConfigurationImportSelector.class) //META-INF/spring.factories
@ComponentScan("com.atguigu.boot") #扫描主启动类下所有组件2.1.效果体现
2.1.1.What(效果)
自动配置好了一切,包括SpringMVC常用组件(功能)
搜一下以前的帖子,Spring整合SpringMVC的帖子发现xml会配一大堆东西!!!这些组件springBoot启动的时候会把组件都装配到容器中,不用配。
- 前端控制器DispatcherServlet:拦截所有的前端的请求;
- 字符编码characterEncodingFilter:解决返回中文字符串乱码问题;
- 视图解析器viewResolver:对返回的视图进行渲染呈现;
- 文件上传解析器multipatResolver:文件上传;
代码验证:打印所有启动时候装载的 Beans
//返回一个IOC容器
ConfigurableApplicationContext run = SpringApplication.run(MainApplication.class, args);
String[] names = run.getBeanDefinitionNames();
Arrays.stream(names).forEach(System.out::println);2.1.2.Why(怎么做到的)
这个jar里有几乎SpringBoot所需要全场景,有很多爆红的类其实导入相应的dependency就不会爆红了
spring-boot-starter-web->spring-boot-starter->spring-boot-autoconfigure
For example:以MySQL 配置数据源为例:DataSourceProperties
2.2.@AutoConfigurationPackage🌟
ChatGPT:转念一想,这两个注解都如字面意思 这样就很好区分异同
springboot @ComponentScan和@AutoConfigurationPackage的区别
@ComponentScan和@AutoConfigurationPackage都是 Spring Boot 中用来扫描组件和自动配置的注解,它们的区别在于:
@ComponentScan:这个注解是用来指定 Spring 扫描组件的位置,会扫描指定的包及其子包中的所有类,找到标记为@Component、@Service、@Repository等注解的类,并将其注册为 Spring 的 Bean。@AutoConfigurationPackage:这个注解是用来指定自动配置所在的包,它会扫描指定的包及其子包中的所有类,找到标记为@Configuration的类,并将其注册为 Spring 的 Bean。简而言之,
@ComponentScan和@AutoConfigurationPackage都是用来扫描组件的注解,区别在于@ComponentScan扫描的是标记了特定注解的组件类,而@AutoConfigurationPackage扫描的是配置类。在 Spring Boot 应用中,通常会在启动类上使用@SpringBootApplication注解,该注解中已经包含了@ComponentScan和@AutoConfigurationPackage,因此一般不需要单独使用这两个注解。
2.3.@Import(AutoConfigurationImportSelector.class)🌟
1、利用getAutoConfigurationEntry(annotationMetadata);给容器中批量导入一些组件 2、调用List<String> configurations = getCandidateConfigurations(annotationMetadata, attributes)获取到所有需要导入到容器中的配置类 3、利用工厂加载 Map<String, List<String>> loadSpringFactories(@Nullable ClassLoader classLoader);得到所有的组件 4、从META-INF/spring.factories位置来加载一个文件。 默认扫描我们当前系统里面所有META-INF/spring.factories位置的文件 spring-boot-autoconfigure-2.3.4.RELEASE.jar包里面也有 META-INF/spring.factories
作用:文件里面写死了spring-boot一启动就要给容器中加载的所有配置类,并不是所有都生效@Condition 例如AOP、Batch就需导入相关包才生效
学习:可以找找各个第三方jar包里面的 xxxxxAutoConfiguration 分析是否生效装配进来了
总结:
用户配的优先 @ConditionalOnMissingBean
如果用户配的bean名字不符合规范,就给你纠正过来,如下给容器中加入了文件上传解析器:
@Bean
@ConditionalOnBean(MultipartResolver.class) //容器中有这个类型组件
@ConditionalOnMissingBean(name = DispatcherServlet.MULTIPART_RESOLVER_BEAN_NAME) //容器中没有这个名字 multipartResolver 的组件
public MultipartResolver multipartResolver(MultipartResolver resolver) {
//给@Bean标注的方法传入了对象参数,这个参数的值就会从容器中找。
//SpringMVC multipartResolver。防止有些用户配置的文件上传解析器不符合规范
// Detect if the user has created a MultipartResolver but named it incorrectly
return resolver;
}- 一般这些自动配置类都绑了xxxxProperties里面拿。xxxProperties和配置文件进行了绑定
判断场景自动配置那些生效那些没生效:
自己分析,引入场景对应的自动配置一般都生效了
配置文件中debug=true开启自动配置报告。Negative(不生效)\Positive(生效)【方便分析源码】
- 自定义器 XXXXXCustomizer;【不熟】
3.自动配置-实践
想不起配置文件怎么配 SQL 于是有了下文
以MySQL 配置数据源为例:DataSourceProperties
DataSourceAutoConfiguration -> 组件 -> DataSourceProperties -> application.properties总结:
SpringBoot先加载所有的自动配置类 xxxxxAutoConfiguration
每个自动配置类按照条件进行生效,默认都会绑定配置文件指定的值。xxxxProperties里面拿。xxxProperties和配置文件进行了绑定
生效的配置类就会给容器中装配很多组件
只要容器中有这些组件,相当于这些功能就有了
定制化配置
- 用户直接自己@Bean替换底层的组件
- 用户去看这个组件是获取的配置文件什么值就去修改。
xxxxxAutoConfiguration ---> 组件 ---> xxxxProperties里面拿值 ----> application.properties




Ⅰ、Spring 学习
1.Spring提供的IOC容器实现的两种方式(两个接口)
ApplicationContext context = new ClassPathXmlApplicationContext("beans.xml");
a)BeanFactory接口:IOC容器基本实现是Spring内部接口的使用接口,不提供给开发人员进行使用(加载配置文件时候不会创建对象,在获取对象时才会创建对象。)
b)ApplicationContext接口:BeanFactory接口的子接口,提供更多更强大的功能,提供给开发人员使用(加载配置文件时候就会把在配置文件对象进行创建)推荐使用!
ps:容器的话主要有两个,BeanFactory和ApplicationContext,他们简单区别就是:BeanFactory是低级容器,延迟加载bean,编程时方式创建;ApplicationContext是 BeanFactory 的子接口,是高级容器,一次性加载bean,以声明式方式创建
//upupor TrueSend trueSend = SpringContextUtils.getBean(TrueSend.class);
@Component
public class SpringContextUtils implements ApplicationContextAware {
//UNKNOWN 这里不用注入吗 XD 因为实现了 ApplicationContextAware 此接口重写方法拿到了
private static ApplicationContext applicationContext;
@Override
public void setApplicationContext(ApplicationContext applicationContext) {
SpringContextUtils.applicationContext = applicationContext;
}
.......2.IOC操作Bean管理
a)Bean管理就是两个操作:(1)Spring创建对象;(2)Spring注入属性
基于(2)现在理解了:
a)set方式注入
//(1)传统方式: 创建类,定义属性和对应的set方法
public class Book {
//创建属性
private String bname;
//创建属性对应的set方法
public void setBname(String bname) {
this.bname = bname;
}
}<!--(2)spring方式: set方法注入属性-->
<bean id="book" class="com.atguigu.spring5.Book">
<!--使用property完成属性注入
name:类里面属性名称
value:向属性注入的值
-->
<property name="bname" value="Hello"></property>
<property name="bauthor" value="World"></property>
</bean>b)有参构造函数注入
补充:构造参数注入 vs setter注入
以前一直不懂 构造参数注入
@RequiredArgsConstructor //XD lombook
@RequestMapping("member")
public class MemberController {
private final MemberOperateService memberBusinessService; //XD finalsetter 注入估计就是 @Autowired 好像不是
Q&A 因为有三种注入方式:
1.set方法注入 2.构造方法注入 3.@autowire自动注入
总结起来:
@RequiredArgsConstructor与private final一起使用是一种构造函数注入的方式。@Autowired注解可以用于字段、setter方法或构造函数,用于实现自动装配(autowiring),可以通过setter注入或构造函数注入的方式来注入依赖项。
@Resource默认通过名称注入,如名称无法找到则通过类型注入; @Autowired默认通过类型注入,如存在多个类型则通过名称注入,也可以配合@Qualifier注解,在@Qualifier中指定bean的名字来注入你想要的那个bean
其实lombok有个@RequiredArgsConstructor注解,可以帮你用构造器注入
3.Bean生命周期
bean 的后置处理器,bean 生命周期有七步 (正常生命周期为五步,而配置后置处理器后为七步)
- 实例化
- 属性赋值 (构造参数注入,setter注入等)
- 初始化 (检查aware接口,前置处理,后置处理等,这个过程中可能自定义了一些初始化之前的操作和之后的操作)
- 使用
- 销毁 (销毁前可能自己配置了一些销毁之前的方法)
第一步:Construction 构造Bean对象
第二步:set Bean 属性值
(1)把 bean 实例传递 bean 后置处理器的方法 postProcessBeforeInitialization
第三步:init调用自定义的初始化方法 //这前三步在 new ClassPathXmlApplicationContext("beans-test.xml"); 就搞完
(2)把 bean 实例传递 bean 后置处理器的方法 postProcessAfterInitialization
第四步:获取实例化后的 Bean 可以开始使用 Bean org.example.bean.BeanLife@649bec2e
第五步:destroy调用自定义销毁的方法 //手动让 bean 实例销毁 context.close(); //ClassPathXmlApplicationContext
<bean id="beanLife" class="org.example.bean.BeanLife" init-method="init" destroy-method="destroy">
<property name="properties" value="属性XD"/>
</bean>
<!--配置后置处理器-->
<bean id="myBeanPost" class="org.example.config.MyBeanPost"/>public class MyBeanPost implements BeanPostProcessor //创建后置处理器实现类,对应(1)(2)
4.AOP
RuoYi、upupor 自定义注解全是和 AOP 相关
除了有个注解是配合SpringSecurity实现注解地方放行访问 (RUOYI)
学习手册.pdf 补充:
多个切面的情况下,可以通过 @Order 指定先后顺序,数字越小,优先级越高。
说说你平时有用到AOP吗? (例子很好,要知行合一)
PS:这道题老三的同事面试候选人的时候问到了,候选人说了一堆AOP原理,同事 就势来一句,你能现场写一下AOP的应用吗?结果——场面一度很尴尬。虽然我对面 试写这种百度就能出来的东西持保留意见,但是还是加上了这一问,毕竟招人最后 都是要撸代码的。
这里给出一个小例子,SpringBoot项目中,利用AOP打印接口的入参和出参日志,以 及执行时间,还是比较快捷的。
引入依赖:引入AOP依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-aop</artifactId> </dependency>自定义注解:自定义一个注解作为切点
@Retention(RetentionPolicy.RUNTIME) @Target({ElementType.METHOD}) @Documented public @interface WebLog { }配置AOP切面:
- @Aspect:标识切面
- @Pointcut:设置切点,这里以自定义注解为切点,定义切点有很多其它种方 式,自定义注解是比较常用的一种。
- @Before:在切点之前织入,打印了一些入参信息
- @Around:环绕切点,打印返回参数和接口执行时间
@Aspect @Component public class WebLogAspect { private final static Logger logger = LoggerFactory.getLogger(WebLogAspect.class); /** * 以自定义 @WebLog 注解为切点 **/ @Pointcut("@annotation(cn.fighter3.spring.aop_demo.WebLog)") public void webLog() {} /** * 在切点之前织入 */ @Before("webLog()") public void doBefore(JoinPoint joinPoint) throws Throwable { // 开始打印请求日志 ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes(); HttpServletRequest request = attributes.getRequest(); // 打印请求相关参数 logger.info("============ Start=========================================="); // 打印请求 url logger.info("URL : {}", request.getRequestURL().toString()); // 打印 Http method logger.info("HTTP Method : {}", request.getMethod()); // 打印调用 controller 的全路径以及执行方法 logger.info("Class Method : {}.{}", joinPoint.getSignature().getDeclaringTypeName(), joinPoint.getSignature().getName()); // 打印请求的 IP logger.info("IP : {}", request.getRemoteAddr()); // 打印请求入参 logger.info("Request Args : {}",new ObjectMapper().writeValueAsString(joinPoint.getArgs())); } /** * 在切点之后织入 */ @After("webLog()") public void doAfter() throws Throwable { // 结束后打个分隔线,方便查看 logger.info("================== End==========================================="); } /** * 环绕 */ @Around("webLog()") public Object doAround(ProceedingJoinPoint proceedingJoinPoint) throws Throwable { //开始时间 long startTime = System.currentTimeMillis(); Object result = proceedingJoinPoint.proceed(); // 打印出参 logger.info("Response Args : {}", new ObjectMapper().writeValueAsString(result)); // 执行耗时 logger.info("Time-Consuming : {} ms", System.currentTimeMillis() - startTime); return result; } }使用:只需要在接口上加上自定义注解
@GetMapping("/hello") @WebLog(desc = "这是一个欢迎接口") public String hello(String name){ return "Hello "+name; }

静态代理为什么是静态代理?
aop就是用的代理实现,代理分为静态代理和动态代理
静态代理比如 AspectJ,AOP框架会在编译阶段生成AOP代理类,属于编译时的增强
动态代理比如 jdk动态代理 和 CGLIB ,AOP框架不会去修改字节码,而是每次运行时在内存临时为方法生成一个AOP对象,AOP对象包含了目标对象的全部方法,在特定切点做了增强处理,并回调原对象的方法。
当时的回答:spring使用的就是动态代理,动态代理有两个:jdk自带的和Cglib,jdk的代理效率会高一些,Cglib是动态代码生成库
Spring 框架一般都是基于 AspectJ 实现 AOP 操作,AspectJ 不是 Spring 组成部分,独立 AOP 框架,一般把 AspectJ 和 Spirng 框架一起使 用,进行 AOP 操作
补充:Spring AOP 和 AspectJ AOP 有什么区别?
Spring AOP 属于运行时增强,而 AspectJ 是编译时增强。 Spring AOP 基于代理(Proxying),而 AspectJ 基于字节码操作(Bytecode Manipulation)。
Spring AOP 已经集成了 AspectJ ,AspectJ 应该算的上是 Java 生态系统中最完整的 AOP 框架了。AspectJ 相比于 Spring AOP 功能更加强大,但是 Spring AOP 相对来说更简单,
如果我们的切面比较少,那么两者性能差异不大。但是,当切面太多的话,最好选择 AspectJ ,它比 Spring AOP 快很多。
著作权归所有 原文链接:https://javaguide.cn/system-design/framework/spring/spring-knowledge-and-questions-summary.html
RuoYi 补充 AOP 实操
1.@Before 使用场景:限流处理
@Aspect //切面声明?
@Component
public class RateLimiterAspect{
@Before("@annotation(rateLimiter)")
public void doBefore(JoinPoint point, RateLimiter rateLimiter)Redis Key: rate_limit:com.ruoyi.web.controller.system.SysUserController-list
JoinPoint point 这个类可以获取 AOP 前置通知(Before Advice)注解标注的类名及其方法名【反射】
2.@AfterReturning 使用场景:日志记录 增删改
处理完请求后执行
Upupor 补充 AOP 实操
@Around使用场景:博客下面统计记录 响应时间 (spring的 StopWatch 类 + @Around 实现!!!)
@Around("controllerLog()")
public Object doAround(ProceedingJoinPoint proceedingJoinPoint) throws Throwable {
// 调用业务方法
result = proceedingJoinPoint.proceed(); //XD 这里调用目标方法,这之前的代码都是【前置逻辑】 下面的代码都是【后置逻辑】Q: 为什么要用Threadlocal来包装stopwatch呢? 作者回复: 我在执行前后需要使用同一个StopWatch,所以需要有个地方暂存一下,而且每次为请求计时都需要一个不同的StopWatch,不能共用一个,既然是一个线程在处理一个请求,那比较简单的方法就是放在ThreadLocal里。
- 核实 upupor 是不是也是这样 geektime.spring.springbucks.waiter.controller.PerformanceInteceptors
5.Spring 事务
问:项目中什么地方用到了 AOP 在 Spring 中进行事务管理中就用到了!!!
声明式事务:就是用注解的方式/xml开启事务底层使用的是 AOP,相对的手动写代码开事务关事务
6.设计模式
至少前5种答出来
- IOC 工厂模式 : Spring 容器本质是一个大工厂,使用工厂模式通过 BeanFactory、 ApplicationContext 创建 bean 对象。
- AOP 代理模式 : Spring AOP 功能就是通过代理模式来实现的,分为动态代理和静 态代理。
- IOC 单例模式 : Spring 中的 Bean 默认都是单例的,这样有利于容器对Bean的管理。
- 模板模式 : Spring 中 JdbcTemplate、RestTemplate 等以 Template结尾的对数据 库、网络等等进行操作的模板类,就使用到了模板模式。
- 观察者模式: Spring 事件驱动模型就是观察者模式很经典的一个应用。
- 可以将观察者模式看作是发布订阅模式的一个特例
- 在Spring框架中,事件驱动的编程模型是基于发布订阅模式的。
- 适配器模式 :Spring AOP 的增强或通知 (Advice) 使用到了适配器模式、Spring MVC 中也是用到了适配器模式适配 Controller。
- 策略模式:Spring中有一个Resource接口,它的不同实现类,会根据不同的策略 去访问资源。
7.哪些模块组成
https://juejin.cn/post/6997930907227127838
- 四个核心模块

- 根据
Spring源码模块中的gradle依赖,可以整理出这么一张依赖关系图

------分割线------
1)常用注解
搞个时间重新排个版!知识待完善
@EnableTransactionManagement // 开启注解事务管理,等价于xml配置方式的 <tx:annotation-driven />Spring提供了一个@EnableTransactionManagement 注解以在配置类上开启声明式事务的支持。添加该注解后,Spring容器会自动扫描被@Transactional注解的方法和类。
@Retention(RetentionPolicy.RUNTIME)
- 用于使注解在运行时可以通过反射来访问和处理。这对于某些需要在运行时动态处理注解的场景非常有用
- RuoYi 运行时候动态获取注解信息,比如
@PostConstruct
@PostConstruct是一个在 Spring 框架中常用的注解,它用于指定在对象创建完成后需要立即执行的方法。当使用@PostConstruct注解标记一个方法时,Spring 在实例化该对象并完成依赖注入后,会自动调用该方法。- RuoYi 中用来开启 quartz
@RquestBody
获取请求体,必须发送POST请求。SpringMVC自动将请求体的数据**(json),转为对应Java对象**(+形参Entity上)
//以较简单的User对象接收前端传过来的ison数据(SpringMVC会智能的将符合要求的数据装配进该User对象中) public String test(@RequestBody User user){}
@ResponseBody
例如,异步获取
json数据,加上@Responsebody注解后,就会直接返回json数据。@RestController = @Controller +
@ResponseBody@ExceptionHandler(Exception.class) @ResponseBody //返回json数据 public Result error(Exception e){ e.printStackTrace(); return Result.fail(); //本来这里返回 Result 对象,但是加上上面注解。会返回 JSON(@ResponseBody) }
@Scope
配置类里面使用@Bean标注在方法上给容器注册组件,默认也是单实例的
//@Scope("prototype") // 现在还不是多例,还需要指定代理模式 //* 原生 Spring JDK代理 * 现在 SpringBoot 2.X 之后都是CGlib,这里用 CGlib @Scope(value = "prototype", proxyMode = ScopedProxyMode.TARGET_CLASS)
@Value
- 1)必须把当前类加入spring的容器管理@Component,注意要在主启动类下,测试类的话用SpringBoot的测试注解,这个也分4/5注意。(容易忽略,不加 [貌似] 得到的为 null)
- 2)变量不能用static修饰!!!
- 如果想要注入静态 spring @value 注入static 注入静态变量方法
- **先说明冒号的作用 :可以设置默认值 **@Value("${prop.url:'http://myurl.com'}")
@SpringBootApplication()
- 适用场景:pom 引入的 Common 有数据源,但是本 Demo 不需要。启动报错要求配
- 后话:个人觉得pom exclude 应该也行
@EnableConfigurationProperties
- 说白了 @ConfigurationProperties 相当于把使用 @ConfigurationProperties 的类进行了一次注入 因为这个类没有@Conponent,用这种方法放到 IOC 容器中才能用 只有容器中的组件才能有SpringBoot提供的强大的功能
- 场景:如果@ConfigurationProperties是在第三方包中,那么@component是不能注入到容器的。只有@EnableConfigurationProperties才可以注入到容器。 RedisCacheConfiguration配置kv的序列化的时候需要把其它配置也给拿上就需要CacheProperties放入容器使用
@ConfigurationProperties
- 解决:以前得IO流拿properties里的k v
@Import & @ComponentScan
- 我使用的场景:配置类放在 common 模块,其它模块都来用这个配置类
- 导入组件默认组件名字是 com.example.boot.bean.Cat 全类名
- 也可以导入dependence jar里的class
@PostConstruct
- 场景:MyRabbitConfig对象创建完成以后,执行这个方法
rabbitTemplate.setConfirmCallback用于设置确认回调 ConfirmCallback
- 场景:MyRabbitConfig对象创建完成以后,执行这个方法
@RequestParam,@PathParam,@PathVariable等注解区别
@PathVariable("page")
@GetMapping(value = "/{page}.html") public String listPage(@PathVariable("page") String page) { return page; }
使用@RequestParam时,URL是这样的:http://host:port/path?参数名=参数值
使用@PathVariable时,URL是这样的:http://host:port/path/参数值
@PathParam 发现post请求的话只能用这个来拿参数 注意参数过长拿不到需要用request类拿
My:应该是Get URL有大小限制? 也不对request不是拿到了吗
@PathParam("imegse") String imageBase64 //@PostMapping("/photo") 拿不到参数 String channel = request.getParameter("imegse"); //能拿到
@Builder
Lombok annotation为你的类生成相对略微复杂的构建器API,放随意参数的构造器 链式调用就行
User.builder() .userName("hh") .passWord("123");
@Bean
// @Autowired // CacheProperties cacheProperties; //因为下面是 @Bean 直接放参数用就行! @Bean //原来@Bean注解想容器注入对象的时候,会自动将容器中已经有的对象传入到@Bean注解的方法参数中 public RedisCacheConfiguration redisCacheConfiguration(CacheProperties cacheProperties) { //这个参数能拿值? 这个方法就是给容器放东西,方法传的所有参数所有参数都会从容器中进行确定 所以会自动去IOC中拿
@GetMapping
//场景:return String 内容是支付宝付款页面 @ResponseBody @GetMapping(value = "/aliPayOrder",produces = "text/html")
@ComponentScan("com.example") -> @SpringBootApplication(scanBasePackages = "com.example")
@Configuration(proxyBeanMethods = false)//默认是true //告诉SpringBoot这是一个配置类 == 配置文件
底层会有非常多这样的写法,为的就是加速容器启动过程,减少判断(前提:类组件之间无依赖关系)
MyConfig bean = run.getBean(MyConfig.class); System.out.println(bean); //`com.example.boot.config.MyConfig$$EnhancerBySpringCGLIB$$1@38fc34fd` 默认是Full模式,每一次都从容器中拿 相对的还有Lite即false模式,为什么这么叫因为这样不用去容器中对照来一个返回一个! 最佳实战:别人不依赖这些组件(Person里面拿Pet)就给调成false System.out.println(bean.ss() == bean.ss()); //true最佳实战:
配置 类组件之间无依赖关系用Lite模式加速容器启动过程,减少判断
配置类组件之间有依赖关系,方法会被调用得到之前单实例组件,用Full模式
Mark!!!Bean的加载顺序 在spring ioc的过程中,
- 1)优先解析@Component,@Service,@Controller...注解的类。
- 2)其次解析配置类,也就是@Configuration标注的类
- 3)最后开始解析配置类中定义的bean。
但是tomXXX的条件注解依赖的是user01,user01是被定义的配置类中的, 所以此时配置类的解析无法保证先后顺序,就会出现不生效的情况。 me:所以才会有condition这些?
@ImportResource("classpath:beans.xml")
- 这里之所以要classpath,个人理解:resources不是相对路径
- 总有些老jar包或公司老配置需要的
@ControllerAdvice
- 基于 AOP 实现,不改变源代码增加原功能
@RestControllerAdvice
@RestControllerAdvice是@ControllerAdvice的衍生注解,专门用于处理RESTful风格的控制器。与@ControllerAdvice类似, 使用@RestControllerAdvice的好处是,它不仅会处理异常,还会以RESTful风格返回响应,而不仅仅是视图。这对于构建RESTful API非常方便。@RestControllerAdvice 是 Spring MVC 提供的一个注解,用于统一处理所有 Controller 层抛出的异常。当 Controller 层抛出异常时,可以使用 @RestControllerAdvice 注解的类来捕获并处理异常,从而对异常进行统一处理。
@RestControllerAdvice 注解的类通常会包含多个 @ExceptionHandler 注解的方法,每个 @ExceptionHandler 注解的方法用于处理不同类型的异常。例如,以下代码演示了如何使用 @RestControllerAdvice 注解处理 RuntimeException 类型的异常
@RestControllerAdvice public class GlobalExceptionHandler { @ExceptionHandler(RuntimeException.class) public ResponseEntity<String> handleRuntimeException(RuntimeException ex) { return ResponseEntity .status(HttpStatus.INTERNAL_SERVER_ERROR) .body("Internal Server Error"); } }**总结:**通过 @RestControllerAdvice 注解,我们可以将所有 Controller 层抛出的异常集中处理,避免代码重复,提高代码复用性和可维护性。同时,由于 @RestControllerAdvice 注解是基于 AOP 实现的,因此可以很方便地添加全局异常处理逻辑,例如日志记录、邮件通知等。
@ServletComponentScan
- Servlet(控制器)、Filter(过滤器)、Listener(监听器)可以直接通过@WebServlet、@WebFilter、@WebListener注解自动注册到Spring容器中,无需其他代码。
2)技术点
1)一些小点
classpath 和 classpath* 区别:
- classpath:只会到你的class路径中查找找文件。 classpath*:不仅包含class路径,还包括jar文件中(class路径)进行查找
问题提出: <!-- 指定MyBatis Mapper文件的位置 --> <!-- 我就是这里配错了找了半天!!!注意加上 /*.xml --> <!-- 提出问题:在引入资源文件时,classpath 什么时候用,什么时候不用? 以前这个错误我踩过两次坑,找了很久!!! --> <!--猜测:引用包时不加,引用具体文件时候加?--> 目前的答案: classpath:只会到你的class路径中查找找文件; classpath*:不仅包含class路径,还包括jar文件中(class路径)进行查找 ---- 够深入的吧 classpath路径是来引用文件的,在编译生成的项目下的bulid/classes/ 下具有的文件都是classpath 路径下的文件,都可以通过classpath:方法获取。 如何获取项目类编译后的路径 **String path = 类名.class.getClassLoader().getResource("").getPath();** "**/" 表示的是任意目录; "**/applicationContext-*.xml" 表示任意目录下的以"applicationContext-"开头的XML文件。我 download 了upupor的开源项目发现项目里的数据库敏感信息都是 ${} 方式给的!!!
在 Spring Boot 项目的 YAML 配置文件中,
${}是用于引用外部属性或配置的占位符。你可以为这些占位符提供具体的值,以替换配置文件中的${}表达式。有几种方式可以给
${}占位符提供值:application.properties/application.yml 文件:在 Spring Boot 项目的
src/main/resources目录下,你可以创建一个application.properties文件(或application.yml,根据你的选择)来提供属性的具体值。例如,如果你在配置文件中有${my.property}占位符,那么你可以在application.properties文件中添加以下内容:my.property=具体的值命令行参数:你可以在启动项目时通过命令行参数来传递属性值。例如,使用以下命令启动 Spring Boot 项目,并为
${my.property}提供具体值: 【idea Environment variables 里面给也行!!!】java -jar myproject.jar --my.property=具体的值环境变量:你可以将属性值设置为环境变量,并在项目启动时读取这些环境变量。例如,将
${my.property}设置为环境变量MY_PROPERTY,然后在项目启动时,它将自动读取该环境变量的值。
这些是最常用的给
${}占位符提供值的方法。你可以根据实际需求选择适合的方式来提供属性的具体值。需要注意的是,如果你在
application.properties文件中定义了属性的默认值,那么当没有其他方式提供属性值时,将使用该默认值。例如:my.property=默认值如果没有其他方式提供
${my.property}的具体值,它将默认使用 "默认值"。希望这可以帮助你给 Spring Boot 项目的 YAML 文件中的
${}占位符提供具体的值。如有进一步的疑问,请随时提问。
SpringBoot,因为默认加入了Slf4j-api和logback的依赖,所以只需要添加lombok的依赖即可.
- 注意IDEA 2020.3以及之后的版本内置了lombok插件
在 Spring Boot 中,您可以使用
logging.level属性来配置不同包或类的日志级别。通过配置 Spring Boot 的日志级别,您可以同时控制 MyBatis-Plus 和 MyBatis 的日志输出。
logging: level: com.zzq.gulimall: DEBUG —————————————————————— logging: level: com.example.distributedlock.dao: debug #一定要加这一行指定目录,不然报错
Spring Boot 2.+默认连接池HikariCP ”黑卡丽“,光的意思很快 日本人发明。区分Druid连接池为监控而生扩展点多..
Spring MVC 的默认json解析器便是 Jackson
- 如果用了 Nacos 会依赖导入 fastjson(雷神用了这个)
快速定位报错原因

image-20221017164745509
3)Test 测试类:
org.junit.jupiter.api.Test和org.junit.Test区别
- 现在需要知道!主要是 spring boot 2.2之前使用的是 Junit4 之后是 Junit5,还需知道他们两个有什么区别看网站!
- 都要 public
- @RunWith
- 现在需要知道!主要是 spring boot 2.2之前使用的是 Junit4 之后是 Junit5,还需知道他们两个有什么区别看网站!
关于@RunWith(SpringRunner.class)的作用
SpringBoot 测试类 需要从容器中获取实例是需要加上该注解,否则空指针,管你是啥IDE。貌似是Junit4用的注解
//不加@RunWith(SpringRunner.class)就取不到容器中的 Bean @Autowired private RestHighLevelClient client; @Test public void contextLoads() { System.out.println(client); //null }
单元测试类中,初始化方法
//单元测试类中,初始化方法 alt+insert SetUpMethod //视频中是测 Jedis 用这个方法连 Redis @BeforeEach void setUp()
补充:@SpringBootTest
我们新建 SpringBoot 程序发现 src 包和 test 包路径一开始初始化就是一样的!
- 因为测试类包名得和主启动类一致才能跑测试类
- 如果不想修改包名,那么需要在注解上加上@SpringBootTest(classes = xxx.class)
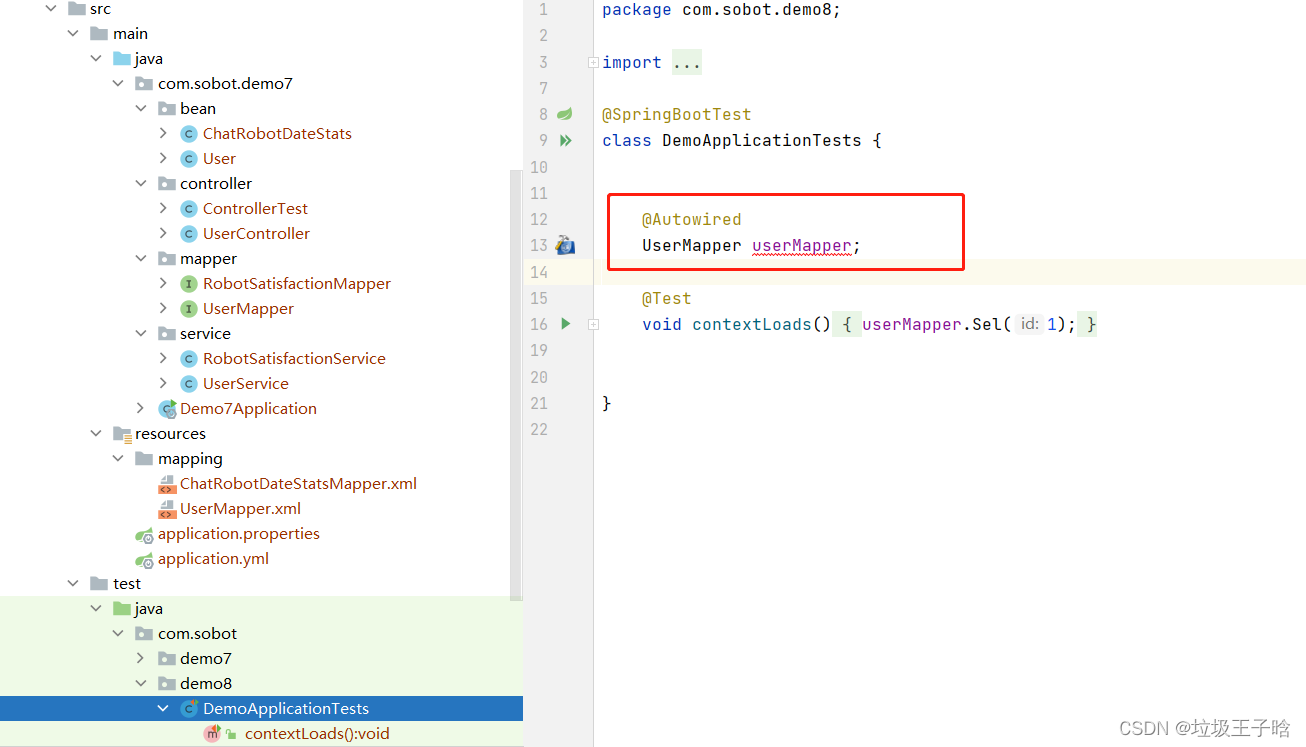
- 但这里会产生额外的问题,因为此时springboot已经把该类当成一个独立的测试类了,这意味着这个测试类对应独立的IOC容器,所以此时我们无法注入到main包中的组件,案例如下,main包下的路径是com.sobot.demo7,而同理,test包下com.sobot.demo7路径下测试类,可以正常装配userMapper组件com.sobot.demo8路径下测试类,则根本无法找到userMapper这个组件
在这里插入图片描述
- 但这里会产生额外的问题,因为此时springboot已经把该类当成一个独立的测试类了,这意味着这个测试类对应独立的IOC容器,所以此时我们无法注入到main包中的组件,案例如下,main包下的路径是com.sobot.demo7,而同理,test包下com.sobot.demo7路径下测试类,可以正常装配userMapper组件com.sobot.demo8路径下测试类,则根本无法找到userMapper这个组件
4)有参数的@Bean,@Configuration注解
:)以前竟然不知道
// @Autowired
// CacheProperties cacheProperties; //因为下面是 @Bean 直接放参数用就行!
@Bean //原来@Bean注解想容器注入对象的时候,会自动将容器中已经有的对象传入到@Bean注解的方法参数中
public RedisCacheConfiguration redisCacheConfiguration(CacheProperties cacheProperties) { //这个参数能拿值? 这个方法就是给容器放东西,方法传的所有参数所有参数都会从容器中进行确定 所以会自动去IOC中拿5)数据校验
6)拦截器
实现步骤:
com.zzq.gulimall.cart.intercept.CartIntercept #编写拦截器
public class CartIntercept implements HandlerInterceptor
com.zzq.gulimall.cart.config.GulimallWebConfig #注册拦截器
@Configuration
public class GulimallWebConfig implements WebMvcConfigurer为什么InterceptorRegistry不需要调用addPathPatterns("/**")也可以拦截所有请求 我在源码看到的是 private final List<String> includePatterns = new ArrayList(); 不能理解为什么会默认拦截所有请求
InterceptorRegistry 是 Spring 框架中用于管理拦截器的注册表,其本身并不具备拦截请求的能力。实际上,InterceptorRegistry 中的拦截器在拦截请求时,是由 HandlerMapping 所管理的 HandlerExecutionChain 中的拦截器链来调用的。而 HandlerMapping 中的拦截器链的触发是由 RequestMappingHandlerMapping 实现的。
在 Spring MVC 中,所有请求都会被 RequestMappingHandlerMapping 处理,而 RequestMappingHandlerMapping 会在初始化时自动注册一个拦截器 HandlerInterceptorAdapter,用于拦截所有请求。所以,即使我们没有在拦截器中调用 addPathPatterns("/**") 方法来设置拦截路径,也能默认拦截所有请求。
在实际开发中,如果我们需要自定义拦截器,并且只拦截部分请求,可以使用 addPathPatterns 方法来指定拦截路径。如果需要拦截所有请求,则无需设置拦截路径,InterceptorRegistry 会默认将拦截器添加到拦截器链中。
7)Controller方法常用参数
7.1.Model / RedirectAttributes
可以往 Thymeleaf 携带参数,模拟的 HttpSession
Model 数据是在请求域中的! vs RedirectAttributes 重定向视图(addFlashAttribute方法代表只需要取一次!跳转取到后刷新页面就没了 | addAttribute():将数据放在url后面)
重定向携带数据,利用session原理.将数据放在session中.
只要跳到下一个页面取出这个数据以后,session里面的数据就会删掉
问题:但是他是利用的session原理,所以后期我们需要解决分布式的session问题
8)idea设置程序根目录
在 IntelliJ IDEA 中,你可以设置程序的根目录(Working Directory)来影响程序运行时的默认路径。这个设置决定了程序在启动时的默认工作目录。
以下是在 IntelliJ IDEA 中设置程序根目录的步骤:
- 打开 IntelliJ IDEA,并打开你的项目。
- 在顶部菜单栏中,选择 "Run"(运行)菜单,然后选择 "Edit Configurations"(编辑配置)。
- 在弹出的窗口中,选择你要修改的运行配置(例如,一个 Java Application 或一个 Spring Boot Application)。
- 在右侧面板中,找到 "Configuration" 选项卡。
- 在 "Working directory"(工作目录)部分,选择 "Specified"(指定)选项。
- 点击 "..." 按钮,选择你想要设置为程序根目录的目录。
- 确认设置后,点击 "OK" 保存修改。
现在,当你运行这个配置时,程序将使用你指定的目录作为根目录。在程序中使用相对路径时,它们将以这个根目录为基准。
请注意,这个设置仅影响程序在 IntelliJ IDEA 中运行时的默认工作目录,并不会改变程序在实际部署或运行环境中的行为。在实际部署时,程序的根目录可能由部署环境或命令行参数决定。
8) 实现ApplicationContextAware接口的作用
实现 ApplicationContextAware 接口的作用是允许一个类获取对 Spring 应用程序上下文(ApplicationContext)的访问权限。通过实现该接口,类可以获得对应用程序上下文的引用,从而能够进行更高级别的操作,例如获取和管理 Spring Bean、发布应用程序事件等。
具体来说,当一个类实现了 ApplicationContextAware 接口,它必须实现接口中的 setApplicationContext() 方法。Spring 在初始化该类的实例时,会自动调用 setApplicationContext() 方法,并将应用程序上下文作为参数传递给该方法。通过该方法,类可以将传递的应用程序上下文存储为一个成员变量,以便在需要时进行访问。
下面是一个示例:
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
public class MyBean implements ApplicationContextAware {
private ApplicationContext applicationContext;
@Override
public void setApplicationContext(ApplicationContext applicationContext) {
this.applicationContext = applicationContext;
}
public static <T> T getBean(Class<T> clazz) throws BeansException {
return applicationContext.getBean(clazz);
}
}
-----------------即可在 CcEmailUtils.class 等没有被Spring管理的工具类中使用Spring对象
TrueSend trueSend = SpringContextUtils.getBean(TrueSend.class);通过实现 ApplicationContextAware 接口,类可以直接访问应用程序上下文,从而获得更多的灵活性和功能。例如,可以根据需要获取其他 Bean 的引用、发布应用程序事件、访问配置属性等。
9)Spring-静态资源启用版本控制
upupor blog Spring版本控制yaml+MinIO+Thymeleaf
犹记毕业第一年时,公司每次发布完成后,都会在一个群里通知【版本更新,各部门清理缓存,有问题及时反馈】之类的话。归根结底就是资源缓存的问题,浏览器会将请求到的静态资源,如JS、CSS等文件缓存到用户本地,当用户再次访问时就不需要再次请求这些资源了,以此也是提升了用户体验。但是也正是因为这些资源缓存,导致客户端的静态文件往往不是当前最新版本。后来有同事增加了时间戳、随机数等,确实这也解决了客户端缓存的问题,但是却又带来了新的麻烦,导致每次访问都要请求服务器,无形中增加了服务器的压力。
https://www.cnblogs.com/laoyeye/p/10034617.html
Q&A
Thymeleaf这里@{}会导致 .css 之前会拼接一串-99e54d8e467b26ef66ff560393a00091 为什么?
Thymeleaf中的@{}语法用于生成URL,并在URL中附加上下文路径。在你提供的示例中,.css之前附加的-99e54d8e467b26ef66ff560393a00091是一个哈希值,可能是由于你的应用程序或Thymeleaf的资源管理策略而生成的。
这种哈希值的添加通常是为了解决浏览器缓存的问题。当静态资源(如CSS文件)发生更改时,为了确保浏览器加载最新的版本而不使用缓存,可以通过在URL中添加哈希值来创建一个唯一的URL。当资源发生更改时,哈希值也会随之变化,从而强制浏览器重新加载资源。
在你的示例中,${ossStatic}是一个变量,可能包含了资源的基本URL路径。而@{/semantic-ui/semantic.min.css}则使用了Thymeleaf的URL表达式生成相对于当前请求上下文的CSS文件URL。结合起来,生成的URL将是${ossStatic}的值加上/semantic-ui/semantic.min.css,并附加上哈希值。
如果你想去除哈希值的附加,可以检查你的应用程序或Thymeleaf的资源管理配置,看是否有相关配置项控制哈希值的添加。具体配置方式可能因你所使用的框架或工具而异。
是由Spring配置控制的: 使用MD5生成版本号进行管理 资源名-md5 方式
spring:
# 静态资源启用版本控制
resources:
chain:
strategy:
#MD5实现
content:
enabled: true
paths: /**
注:第二种、版本号实现
spring:
resources:
chain:
strategy:
fixed:
enabled: true
paths: /mods/admin/*.js
version: 20181128
<script src="/20181128/mods/admin/login.js"></script>ps: MD5(Message Digest Algorithm 5)是一种哈希函数,用于将任意长度的数据映射为固定长度的哈希值。因此,可以说MD5是通过哈希实现的。
注 实现该功能的是ResourceUrlEncodingFilter,它在模板运行期会重写资源链接,Thymeleaf,Velocity和FreeMarker会自动配置该filter,JSP需要手动配置。其他模板引擎还没自动支持,不过你可以使用ResourceUrlProvider自定义模块宏或帮助类。
9.1.MinIO处理
upupor博主处理方式为 py 改名用CLI上传文件
我这里就简单粗暴的把 MinIO 的文件全部改名 GPT:递归地处理当前文件夹及其所有子文件夹中的文件,并更改它们的文件名(在文件名的后缀名前附加"-<文件的MD5值>")
import os
import hashlib
def calculate_md5(filename):
md5_hash = hashlib.md5()
with open(filename, 'rb') as f:
for chunk in iter(lambda: f.read(4096), b''):
md5_hash.update(chunk)
return md5_hash.hexdigest()
def rename_files_with_md5(folder_path):
# 定义要处理的后缀名列表
allowed_extensions = ['.svg', '.webp', '.js', '.css', '.png', '.jpeg', '.jpg', '.ico']
for root, dirs, files in os.walk(folder_path):
for filename in files:
file_path = os.path.join(root, filename)
file_name, file_ext = os.path.splitext(filename)
# 检查文件后缀名是否在允许的列表中
if file_ext.lower() in allowed_extensions:
md5_value = calculate_md5(file_path)
new_filename = f"{file_name}-{md5_value}{file_ext}"
new_file_path = os.path.join(root, new_filename)
os.rename(file_path, new_file_path)
## 获取当前文件夹路径
current_folder = os.getcwd()
## 调用函数递归处理文件夹中的文件
rename_files_with_md5(current_folder)10. SpringBoot 配置加载优先级详解
1. 加载位置与顺序
file:./config/
file:./
classpath:/config/
classpath:/- file: 指当前项目根目录
- classpath: 指当前项目的resources目录
2. Q&A
Q: springboot项目同时有application.properties和application-default.properties配置文件,启动应用两个都会生效吗
A: 是的,Spring Boot应用程序同时拥有application.properties和application-default.properties配置文件时,启动应用程序时会同时生效。
先后顺序如下:
application.properties application-{active}.properties(例如,application-dev.properties、application-prod.properties) application-default.properties
详细:
综上,本地及Nacos配置中心共同加载顺序为:
- bootstrap.yaml
- bootstrap.properties
- bootstrap-{profile}.yaml
- bootstrap-{profile}.properties
- application.yaml
- application.properties
- application-{profile}.yaml
- application-{profile}.properties
- nacos配置中心共享配置(通过spring.cloud.nacos.config.shared-configs指定)
- Nacos配置中心该服务配置(通过spring.cloud.nacos.config.prefix和spring.cloud.nacos.config.file-extension指定)
- Nacos配置中心该服务-{profile}配置(通过spring.cloud.nacos.config.prefix和spring.cloud.nacos.config.file-extension、以及spring.profiles.active指定)
因此,配置生效覆盖关系:
对于key名相同,后加载会覆盖掉前加载,故而最终为后加载的配置项生效!
对于key名不同,则直接生效(会加载,但不会被覆盖);
注意:不能理解为文件级整体覆盖,而仅是同名key会被后加载的键值覆盖。
实测 application-default.properties 覆盖 application.properties
ps:
也就是说如果没有指定 {active} & 如果有 default 那么它就会生效
如果你在
application.properties中设置了spring.profiles.active=dev,那么application-default.properties的属性值将不会生效,而是会根据当前活动的配置文件来加载对应的属性。因此,application.properties文件的优先级高于application-default.properties文件。在同一个包下,如果存在同名的属性,则后者会覆盖前者(没有active的话两者都是会生效的)
3)Spring 循环依赖
PS:其实正确答案是开发人员做好设计,别让Bean循环依赖,但是没办法,面 试官不想听这个。
我们都知道,单例Bean初始化完成,要经历三步:
实例化、属性赋值、初始化使用、销毁注入就发生在第二步,属性赋值,结合这个过程,Spring 通过
三级缓存解决了循环依赖: 采用了**“提前暴露”**的策略
- 一级缓存 : Map singletonObjects,单例池,用于保存实例化、属 性赋值(注入)、初始化完成的 bean 实例
- 二级缓存 : Map earlySingletonObjects,早期曝光对象,用于保存实例化完成的 bean 实例
- 三级缓存 : Map> singletonFactories,早期曝光对象工厂,用于保存 bean 创建工厂,以便于后面扩展有机会创建代理对象。
是什么:
在 Spring 应用程序中,一个 Bean 可以依赖于另一个 Bean。当一个 Bean 依赖于另一个 Bean 时,Spring 会在容器中查找并注入该 Bean,以满足当前 Bean 的需求。这种依赖关系可以是单向的,也可以是循环的。循环依赖指的是两个或多个 Bean 之间相互依赖的情况。
举个例子,假设我们有两个 Bean:Bean A 和 Bean B。Bean A 依赖于 Bean B,而 Bean B 也依赖于 Bean A。这种情况下,Spring 容器会在实例化 Bean A 和 Bean B 时发现循环依赖,因为它们相互依赖,无法先创建一个 Bean,然后注入另一个 Bean。
为了解决这个问题,Spring 提供了一个机制,称为“循环依赖解析”。在循环依赖解析期间,Spring 容器会创建一个 Bean 的“早期实例”,然后注入它所依赖的 Bean 的引用。然后,Spring 会继续创建依赖于当前 Bean 的其他 Bean,直到创建完整个 Bean 图,然后将这些 Bean 实例化并注入它们所依赖的 Bean。
总的来说,Spring 的循环依赖解析机制可以帮助开发人员处理循环依赖的情况,但是需要注意的是,过多的循环依赖可能会导致性能问题,并且在解析过程中也可能出现一些不可预测的问题。因此,在设计 Spring 应用程序时,应该尽可能减少循环依赖的使用,并合理设计 Bean 之间的依赖关系。
循环依赖解析是指 Spring 框架中解决循环依赖问题的过程。循环依赖指的是两个或多个 Bean 之间相互依赖的情况,这会导致在 Bean 实例化时出现无限递归的问题,从而导致应用程序启动失败。
在 Spring 容器中,Bean 的创建分为两个阶段:实例化和初始化。在实例化阶段,Spring 会为 Bean 创建一个空对象;在初始化阶段,Spring 会调用 Bean 的构造函数、Setter 方法和其他初始化方法,将 Bean 实例化并初始化。
在解决循环依赖问题时,Spring 采用了“提前暴露”的策略。具体来说,当 Spring 容器在实例化一个 Bean 时,如果发现该 Bean 依赖于另一个还未创建的 Bean,那么 Spring 会先为依赖的 Bean 创建一个“早期暴露的半成品实例”,然后将其注入到当前 Bean 中。这个“早期暴露的半成品实例”是一个未完成初始化的 Bean 实例,它只包含当前 Bean 的依赖项,还没有完成初始化。当所有 Bean 实例都创建完成后,Spring 容器会按照依赖关系将这些“半成品实例”逐个进行初始化,从而完成 Bean 实例化和初始化的过程。
需要注意的是,循环依赖解析的过程中可能会出现死循环的情况,因此 Spring 容器会设置一个默认值为 50 的解析深度限制,防止无限循环。如果超过了这个限制,Spring 会抛出异常,提示存在循环依赖的问题。
4)事件驱动-@EventListener
笔记:https://www.cnblogs.com/dafengdeai/articles/17073114.html
视频:https://www.bilibili.com/video/BV1Cd4y1q7Vm/?spm_id_from=333.337.search-card.all.click&vd_source=0f3bf62c50d57c4a7d85b89b4d2633e0
更好的视频:https://www.bilibili.com/video/BV1Wa4y1477d?p=3&vd_source=0f3bf62c50d57c4a7d85b89b4d2633e0
Spring、SpringBoot常用扩展特性之事件驱动 看代码demo Spring Boot 2 项目
一般搭配以下两个注解一起使用: @EventListener @Async
- @0rder指定执行顺序在同步的情况下生效 看视频也可以搭配这个注解,加个权重 假如多个Listener消费谁先
- @Async 异步执行需要 @EnableAsync 开启异步
事件驱动:即跟随当前时间点上出现的事件,调动可用资源,执行相关任务,使不断出现的问题得以解决,防止事务堆积. 如:注册账户时会收到短信验证码,火车发车前收到提醒,预定酒店后收到短信通知等.如:浏宽器中点击按钮请求后台,鼠标点击变化内容,键盘输入显示数据,服务接收请求后分发请求等.在解决上述问题时,应用程序是由"事件驱动运行的,这类程序在编写时往往可以采用相同的模型实现,我们可以将这种编程模型称为事件驱动模型. (PS:事件驱动模型其实是一种抽象模型,用于对由外部事件驱动系统业务逻辑这类应用程序进行建模.)
debug走到一步,不懂
@Resource
private ApplicationEventPublisher eventPublisher;
//UNKNOWN @FunctionalInterface这里的作用是什么 @EventListener注解!!!!!????
eventPublisher.publishEvent(sendEmailEvent);
--------后来懂了,上面是发布事件了 有相对于的方法监听消费这个事件:--------
@EventListener
@Async
public void sendEmail(EmailEvent emailEvent)
PS:方法参数需要和发布 sendEmailEvent 类型对应, 这样才是一一对应消费重点就是这三个类,搞清就行!!!可以看自己写的代码 注意:ApplicationEvent 可以不实现所以重心其实就两个类
- Spring事件驱动最基本的使用
ApplicationEventPublisher,ApplicationEvent,ApplicationListener(Spring抽象出了这基本的三个。 事件生产方、事件、事件消费方) - ApplicotionEventPublisher 子类
ApplicationContext(在启动类中这个常用一些applicationContext.publishEvent(new ApplicationEvent(this){})) - 事件源、监听器需要被spring管理
- 监听器需要实现ApplicationListener<ApplicotionEvent> xd: 可注解!
- 可体现事件源和监听器之间的松耦合仅依赖spring、ApplicationEvent(发布、监听两个类中都没有另一个的引用!)
XD:
publisher-生产者, Listener(注解到方法)-消费者 publishEvent几次,listener就会消费几次
ApplicationEvent 可以不实现,看顶层的这个接口源码其实也转成了 Object,但是按规范注释来说希望所有的事件类都最好实现 ApplicationEvent
ApplicationEventPublisher.class default void publishEvent(ApplicationEvent event) { publishEvent((Object) event); } //所以事件类没有extends ApplicationEvent也行其实走的是这里 void publishEvent(Object event);
5)SpringMVC的执行流程
- 用户发起请求,请求先被 Servlet 拦截转发给 Spring MVC 框架
- Spring MVC 里面的 DispatcherSerlvet 核心控制器,会接收到请求并转发给HandlerMapping
- HandlerMapping 负责解析请求,根据请求信息和配置信息找到匹配的 Controller类,不过这里如果有配置拦截器,就会按照顺序执行拦截器里面的 preHandle方法
- 找到匹配的 Controller 以后,把请求参数传递给 Controller 里面的方法
- Controller 中的方法执行完以后,会返回一个 ModeAndView,这里面会包括视图名称和需要传递给视图的模型数据
- 视图解析器根据名称找到视图,然后把数据模型填充到视图里面再渲染成 Html 内容返回给客户端
6)CORS 跨域
1995年,同源政策由 Netscape 公司引入浏览器。目前,所有浏览器都实行这个政策
其实,准确的来说,跨域机制是阻止了数据的跨域获取,不是阻止请求发送。
目的:解决springboot跨域请求的问题
第一种 (CorsConfig )
配置 @Bean CorsFilter.class 实现全局跨域,自定义可以访问的地址
第二种:注解方式
@CrossOrigin
日志
日志一般分为日志门面和日志实现:
- 日志门面:常见的 slf4j,apache-common-logging(SPI)
- 日志实现:常见的 log4j1.x、logback、log4j2。
每种日志实现基本都支持不同的配置文件,配置项里面也稍微有些不同。 所以要让日志能正确的输出,需要日志门面、日志实现、日志配置都是正确无误,如果有的应用启动的时候发现无日志,很可能就是上面三者之一存在问题。
OO)碰到过的问题
配置文件热部署:因为这个Bean是启动时加载的,并不是运行时候实时拿
#spring cache
cache:
type: redis
redis:
time-to-live: 100000 #这里我想热部署,搞一下午 jrebel+devtools 都不行还得重启项目静态资源访问不到,因为加了上下文路径
#会导致问题
server:
servlet:
context-path: /yigo
#暂时用的是这个解决
spring:
mvc:
static-path-pattern: /static/**未解决:父 Module有
网上还有个解决方法不理解但可行!<path> 看下面会出其它问题
父有这个按道理子引入父应该也有
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
</dependency>
但是子必须自己导入并加个 optional 才可以
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>@import公共模块的实体类导致lombok的注解失效 Gulimall未解决不做了,是做到限流突然就这个问题不做了

今天重新导入这个项目时,看到 idea 的这个报错突然醒悟!!!看上面笔记当时为什么用它的场景
<!-- 有这个注解会导致 lombok 注解不能正常编译!!!要么加进来要么去掉这个注解!-->
<!-- <annotationProcessorPaths>-->
<!-- <path>-->
<!-- <groupId>org.springframework.boot</groupId>-->
<!-- <artifactId>spring-boot-configuration-processor</artifactId>-->
<!-- <version>2.1.8.RELEASE</version>-->
<!-- </path>-->
<!-- </annotationProcessorPaths>-->多配置激活问题:active profiles 只要写application后面的名字就行,写全了反而失效!!! https://segmentfault.com/q/1010000042312154 也可 --spring.profiles.active=app-bpdev (等同于在idea中配置 如下图位置)

玩转 Spring 全家桶
进 title link 看课程目录、课程介绍
平板问题:
springboot datasource自动装配mysql数据源。。h2为什么不用配数据源
项目需要有自己的parel如何处置springboot的parent
spring-boot-dependencies 放到 <denpendencyManagement>

CommandLineRunner 接口的作用
CommandLineRunner 接口是 Spring Boot 中的一个接口,用于在应用启动后执行一些特定的任务。该接口只有一个方法 run(),当 Spring Boot 应用启动完成后,会自动执行 run() 方法。CommandLineRunner 接口常用于执行一些初始化任务,例如读取配置文件、初始化数据等。与之类似的还有另一个接口 ApplicationRunner,不同之处在于它的 run() 方法接收的参数是一个 ApplicationArguments 对象,该对象封装了命令行参数的信息。通常情况下,我们可以通过实现 CommandLineRunner 或 ApplicationRunner 接口,在 Spring Boot 应用启动后自动执行一些初始化任务。
XD: 其实一样的,可能就是ApplicationArguments这个对象封装了更好操作 程序参数(Program arguments)而已。。。args.getSourceArgs()而 String... args其实一样可以拿参数!!!
java -jar your-project.jar --param1=value1 --param2=value2 通过在 java -jar 命令后添加参数,-- 开头的这些参数被认为是程序参数(Program arguments)。 区分(Environment variables)
以下几种方式都可以被@Value读取到:
1、VM options
java -jar -Dserver.port=8888 -Xms1024m demo.jar 这种方式增加的参数是被设置到应用的系统属性中,可以使用System.getProperty(“server.port”)获取(可以在idea的idea VM options中配置,以空格分隔)
VM options其实就是我们在程序中需要的运行时环境变量,它需要以-D或-X或-XX开头,每个参数使用空格分隔 使用最多的就是-Dkey=value设定系统属性值,比如-Dspring.profiles.active=dev3 -D(defintion)表示自定义参数
2、Program arguments
java -jar demo.jar --server.port=8888 这种方式增加的参数是属于命令行参数,即会从springboot启动时的main方法的String[] args中作为参数传入(可以在idea的program arguments中配置,以空格分隔)
Program arguments为我们传入main方法的字符串数组args[],它通常以--开头,如--spring.profiles.active=dev3
等价于-Dspring.profiles.active=dev3如果同时存在,以Program arguments配置优先
3、Environment variables
从操作系统的环境变量中读取 这种方式的参数即属于操作系统方面的,比如安装jdk时设置的环境变量,定义JAVA_HOME,也可以通过System.getenv(“JAVA_HOME”)获取,(可以在idea的VM Environment variables中配置,以;分隔)
Environment variables没有前缀,优先级低于VM options,即如果VM options有一个变量和Environment variable中的变量的key相同,则以VM options中为准。
4、通过项目中配置文件bootstrap/application文件载入
这种方式是在项目中配置的方式,比较常见
h2数据库为什么不需要配置
嵌入式数据库:H2数据库是一款嵌入式数据库,也就是说它可以被嵌入到Java应用程序中,作为Java程序的一个库。因此,H2数据库不需要独立的服务器进程,不需要额外的配置和管理,只需要在Java应用程序中进行简单的配置即可使用。
配置多数据源
图片很清楚了
我理解:重写三个bean 每加一个数据源就重写一遍放到 Spring Bean
- DataSourceProperties 这样即可在configuration配置我的数据源,区分开其他的加前缀
- DataSource 通过上者的 API Create 数据源,大致就是initializeDataSourceBuilder方法通过 ClassLoader 拿 driverClassName 创建
- PlatformTransactionManager 每个数据库都要设好自己对应的事务管理器
