javaSE
javaSE
建议再优化目录,把自己总结的 / 康师傅的 分起
TOC--MD内容表
Table Of Contents (目录)
Java 集合框架概览

ArrayDeque 双端队列是后出的API,LeetCode常用当模拟栈、队列
* for (int j = 0; j < 100_0000; j++) 其中100_0000是什么
for (int j = 0; j < 100_0000; j++) 可以等同于 for (int j = 0; j < 1000000; j++),都表示循环从0到999999的范围。
下划线的存在只是为了提高代码的可读性,使数字更易于理解和识别。
* i++ 字节码三步,不是原子性
iload iadd istore
联想单例的实例变量+volitile 原因,也是因为原子性才加!
* HashMap 重写了tostring
System.out.println(map); return key + "=" + value;
* ⭐️ ArrayList可以在循环时删除里面的数据吗😡TODO
for删会有问题,要用迭代器删 为什么???
在使用 ArrayList 进行循环时,如果尝试在循环过程中直接删除其中的元素,可能会导致出现问题。
当你使用 ArrayList 的 remove() 方法删除元素时,会改变列表的大小。这会影响到后续的循环迭代,可能导致一些元素被跳过或重复处理。这是因为在删除元素后,后续元素的索引会向前移动,但循环变量可能不会相应地更新。
* ⭐️ Map 也是迭代的时候不能删东西,补充笔记 踩坑严重 最后用两个集合解决
Exception in thread "main" java.util.ConcurrentModificationException:
for (Map.Entry<String,String> e : map2Platform.entrySet()) {
if (e.getKey().matches(pageLayoutId)) {
map2Platform.put(spaceId,e.getValue());
map2Platform.remove(e.getKey());
}
}Map<String, String> toAdd = new HashMap<>();
Set<String> toRemove = new HashSet<>();
// 在遍历结束后修改map
toRemove.forEach(map2Platform::remove);
map2Platform.putAll(toAdd);* 基础知识:unexpected token
才发现成员变量不能 Ait + Enter 生成(必须从左到右写好),局部变量可以。

原因:
Unexpected token的问题在于,在Java中的class下只能进行方法,以及变量等
1.定义方法
2.定义变量
3.在定义变量的同时对变量赋值(同一行)
注意:
class下不能进行逻辑语句的书写,也不能对已经定义的变量进行赋值操作
public class People {
int m = 10,n;
//应该把这些代码定义在一个方法里面
n = 200; //Unexpected token
if(){} //Unexpected token
}* Long 类型比较
如果 == 比较就必须要是 -128 到 127 才相等,有个 private static class LongCache 内部类,其它包装类型也一样
Byte,Short,Integer,Long 这 4 种包装类默认创建了数值 [-128,127] 的相应类型的缓存数据,Character 创建了数值在 [0,127] 范围的缓存数据,Boolean 直接返回 True or False。
Long a = 153434L, b =153434L;
System.out.println(a==b); //false* 在计算机系统中,数值一律用补码来表示(存储)
1)在计算机系统中,数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统一处理;同时,加法和减法也可以统一处理。此外,补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路。
反码解决 减法
1 - 1 = 1 + (-1) = [0000 0001]原 + [1000 0001]原= [0000 0001]反 + [1111 1110]反 = [1111 1111]反 = [1000 0000]原 = -0
补码解决 +-0 【0用[0000 0000]表示,-0即[1000 0000]表示-128】
1-1 = 1 + (-1) = [0000 0001]原 + [1000 0001]原 = [0000 0001]补 + [1111 1111]补 = [0000 0000]补=[0000 0000]原
2)对于两个 int 类型的数相加,如果它们的和超过了 int 类型的最大值,则会发生精度溢出。如果最后的结果还要 /2 可以使用无符号右移解决 我的理解:想象一下两个二进制位相加,溢出也是顶多溢出最高位符号位一位bit。此时 >>> 刚好能解决! 【XD: 妙啊!数学的思想】
- int mid = (left + right) / 2;(精度溢出)
- int mid = left + (right - left) / 2;(✔)
- int mid = (low + high) >>> 1;(✔)
3)一个字节129存不下的,底层是有符号的二进制数来存储的,它是一个环,所以129前面应该是-128,-128前面是,-127。所以答案就是-127。或者算出补码也可得到解
!!!呼应题目,除了0特殊外。关注负数为补码形式!!!
byte b = (byte)129; //-127
//byte range:-128 ~ 127
//127:0111 1111
//128:1000 0000 (-128)
//129:1000 0001 =》(即二进制的10000001在补码表示中解释为-127)* return 碰上 finally
一旦在finally块中使用了return或throw语句,将会导致try块,catch块中的return,throw语句失效
摘自《疯狂Java 讲义》(第三版)P366
* join & yield
在 Java 中,yield() 方法不会显式释放锁资源。它只会让当前线程从运行状态转变为就绪状态,并让出 CPU 时间片给其他线程。但是,线程在就绪状态时仍然持有其所拥有的锁资源。
join() 方法也不会显式释放锁资源。它只会让当前线程等待被调用的线程执行完毕,但是不会释放当前线程持有的锁资源。 thread.Join把指定的线程加入到当前线程,可以将两个交替执行的线程合并为顺序执行的线程。比如在线程B中调用了线程A的Join()方法,直到线程A执行完毕后,才会继续执行线程B。
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new MyThread("Thread 1");
Thread thread2 = new MyThread("Thread 2");
thread1.start();
thread2.start();
// 使用 yield() 方法暂停当前线程,让其他线程有机会执行
Thread.yield();
// 使用 join() 方法等待 thread1 和 thread2 执行完毕
thread1.join();
thread2.join();
System.out.println("All threads have finished execution.");
}* Map接口和Collection接口是同一等级的
* 重载只看参数列表
重载是在同一个类中,有多个方法名相同,参数列表不同(参数个数不同,参数类型不同),与方法的返回值无关,与权限修饰符无关
* 赋值运算有返回值
Java跟C的区别,C中赋值后会与0进行比较,如果大于0,就认为是true;而Java不会与0比较,而是直接把赋值后的结果放入括号。
int a;
System.out.println(a=1); //1* is-a && like-a
Is-a:
**是a:A Is B:A是B(继承关系,继承)。**假设你确定两件对象之间是is-a的关系,那么此时你应该使用继承。比方菱形、圆形和方形都是形状的一种。那么他们都应该从形状类继承。
has-a:
**有a:A has B:A有B(从属关系,聚合)。**假设你确定两件对象之间是has-a的关系,那么此时你应该使用聚合。比方电脑是由显示器、CPU、硬盘等组成的。那么你应该把显示器、CPU、硬盘这些类聚合成电脑类。
like-a:
**像a:A like B:A像B(组合关系,接口)。**假设你确定两件对象之间是like-a的关系,那么此时你应该使用组合。比方空调继承于制冷机,但它同一时候有加热功能。那么你应该把让空调继承制冷机类,并实现加热接
抽象类与其派生类是一种“is-a”关系,即父类和派生子类在概念上的本质是相同的(父子关系,血缘联系,很亲密)。
接口与其实现类是一种“like-a”关系,即接口与实现类的关系只是实现了定义的行为,并无本质上的联系(契约关系,很淡漠的利益关系)。
举个例子:比如说一个动物抽象类,定义了跑的方法、叫的方法,但如果一个汽车类可以实现跑、可以实现叫,它就可以继承动物抽象类吗?!这太不合理了,汽车不是动物呀!而如果通过接口定义跑的方法、叫的方法,汽车类作为实现类实现跑和叫,完全OK很合理,就因为没有继承关系的约束。
* static 初始化 & 类的加载顺序
public class B
{
public static B t1 = new B(); //1
public static B t2 = new B(); //2
{
System.out.println("构造块");
}
static
{
System.out.println("静态块"); //3
}
public static void main(String[] args)
{
B t = new B(); //4
}
}之前我一直有一个误区!就是认为静态块一定是最先初始化的!但是,阿里爸爸今天又用一记重拳猛击我的脸,额,好疼....当时的情况是这样的:
我在牛客网找虐中,碰到了这样的一道题,心中充满了鄙夷,心想"这tm还用看吗,肯定先是静态块,再接着三个构造块,弱鸡题",但是 = = ,答案却是"构造块 构造块 静态块 构造块".
......[黑线|||||||||]
于是总结了一下,以警后世 - -
正确的理解是这样的:
并不是静态块最先初始化,而是静态域.(BM:啊!多么痛的领悟!)
而静态域中包含静态变量、静态块和静态方法,其中需要初始化的是静态变量和静态块.而他们两个的初始化顺序是靠他们俩的位置决定的!
So!
初始化顺序是 t1 t2 静态块
再来一道:
public class Test
{
public static Test t1 = new Test(); //1
{
System.out.println("blockA");
}
static
{
System.out.println("blockB"); //2
}
public static void main(String[] args)
{
Test t2 = new Test(); //3
}
}blockAblockBblockA
总结:
(1) 父类静态对象和静态代码块
(2) 子类静态对象和静态代码块
(3) 父类非静态对象和非静态代码块 【例如下面的Father.class先(3)再(2)】
(4) 父类构造函数(声明肯定都先于构造器,XD:才能拿变量名赋值)
① 默认初始化
② 显式初始化 / 代码块
③ 构造器中初始化
(5) 子类 非静态对象和非静态代码块
(6) 子类构造函数
终结版练习:
字节码 <clinit> <init> 方法 CL 代表 class 有几个构造器就有几个<init>方法
super 写或者不写都有 (注:代码块里的变量、形参都是局部变量)
/**
* 父类初始化<clinit>
* 1、j = method()
* 2、 父类的静态代码块
*
* 父类实例化方法:
* 1、super()(最前)
* 2、i = test() (9)
* 3、子类的非静态代码块 (3)
* 4、子类的无参构造(最后)(2)
*
*
* 非静态方法前面其实有一个默认的对象this
* this在构造器或<init> 他表示的是正在创建的对象,因为咱们这里是正在创建Son对象,所以
* test()执行的就是子类重写的代码(面向对象多态)
*
* 这里i=test() 执行的就是子类重写的test()方法
*/
public class Father {
private int i = test();
private static int j = method();
static{
System.out.println("(1)");
}
Father() {
System.out.println("(2)");
}
{
System.out.println("(3)"); //我主要被这个代码块卡住,其实这块和上面的 int i 同等地位。<inti>() 会执行
}
public int test(){
System.out.println("(4)");
return 1;
}
public static int method() {
System.out.println("(5)");
return 1;
}
}
-----------------------------------------
/**
* 子类的初始化<clinit>
* 1、j = method()
* 2、子类的静态代码块
*
* 先初始化父类 (5)(1)
* 初始化子类 (10) (6)
*
* 子类实例化方法:
* 1、super()(最前
* 2、i = test() (9)
* 3、子类的非静态代码块 (8)
* 4、子类的无参构造(最后)(7)
*/
public class Son extends Father {
private int i = test();
private static int j = method();
static {
System.out.println("(6)");
}
Son() {
super();
System.out.println("(7)");
}
{
System.out.println("(8)");
}
public int test(){
System.out.println("(9)");
return 1;
}
public static int method() {
System.out.println("(10)");
return 1;
}
public static void main(String[] args) {
Son son = new Son();
System.out.println();
Son son1 = new Son();
}
}答案:
(5) (1) (10) (6) (9) (3) (2) (9) (8) (7) \n (9) (3) (2) (9) (8) (7)
* 接口与其实现类
实际上这道题考查的是两同两小一大原则:
方法名相同,参数类型相同
子类返回类型小于等于父类方法返回类型, 子类抛出异常小于等于父类方法抛出异常, 子类访问权限大于等于父类方法访问权限。
* 四种引用类型
被GCroot强引用=Gcroot对象来说,只要有强引用的存在,它就会一直存在于内存中
如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。
如果一个对象只具有软引用,则内存空间足够,垃圾回收器就不会回收它;如果内存空间不足了,就会回收这些对象的内存
一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的空间发现这道题完全没头绪,就去查了一下,感觉说的比较清楚了。
JDK1.2 之前,一个对象只有“已被引用”和"未被引用"两种状态,这将无法描述某些特殊情况下的对象,比如,当内存充足时需要保留,而内存紧张时才需要被抛弃的一类对象。
所以在 JDK.1.2 之后,Java 对引用的概念进行了扩充,将引用分为了:强引用(Strong Reference)、软引用(Soft Reference)、弱引用(Weak Reference)、虚引用(Phantom Reference)4 种,这 4 种引用的强度依次减弱。
一,强引用
Object obj = new Object(); //只要obj还指向Object对象,Object对象就不会被回收 obj = null; //手动置null
只要强引用存在,垃圾回收器将永远不会回收被引用的对象,哪怕内存不足时,JVM也会直接抛出OutOfMemoryError,不会去回收。如果想中断强引用与对象之间的联系,可以显示的将强引用赋值为null,这样一来,JVM就可以适时的回收对象了
二,软引用
软引用是用来描述一些非必需但仍有用的对象。在内存足够的时候,软引用对象不会被回收,只有在内存不足时,系统则会回收软引用对象,如果回收了软引用对象之后仍然没有足够的内存,才会抛出内存溢出异常。这种特性常常被用来实现缓存技术,比如网页缓存,图片缓存等。
在 JDK1.2 之后,用java.lang.ref.SoftReference类来表示软引用。
三,弱引用
弱引用的引用强度比软引用要更弱一些,无论内存是否足够,只要 JVM 开始进行垃圾回收,那些被弱引用关联的对象都会被回收。在 JDK1.2 之后,用 java.lang.ref.WeakReference 来表示弱引用。
四,虚引用
虚引用是最弱的一种引用关系,如果一个对象仅持有虚引用,那么它就和没有任何引用一样,它随时可能会被回收,在 JDK1.2 之后,用 PhantomReference 类来表示,通过查看这个类的源码,发现它只有一个构造函数和一个 get() 方法,而且它的 get() 方法仅仅是返回一个null,也就是说将永远无法通过虚引用来获取对象,虚引用必须要和 ReferenceQueue 引用队列一起使用。
* 构造方法
构造方法就是:public 类名, 没有方法修饰符(PS:可以是其它权限修饰符)
public class MyClass {
long var;
public void MyClass(long param) { var = param; }//(1) 因为用了修饰方法的 void 所以它是一个普通方法!* final 变量
被final修饰的变量是常量,这里的b6=b4+b5可以看成是b6=10;在编译时就已经变为b6=10了
final byte b4=4,b5=6;
b6=b4+b5; //在编译时就已经变为b6=10了,编译通过D选项,final修饰的变量,变量的引用(地址)是不可变得,但是引用的内容是可变的 梅开二度!
链接:https://www.nowcoder.com/questionTerminal/47ffaf4670384e34a925e294fcd686c0
来源:牛客网
final Student t = new Student(); t.setStuName("11"); t.setStuNo(1); //不报错 因此final修饰的可以改变属性
再看我们把Teacher类继承Student:
final Student t = new Student(); t = new Teacher(); //t编译错误,因此不可以再指向其他对象* 静态变量只能在类主体中定义,不能在方法中定义
* pc寄存器 就是 程序计数器
程序计数器是计算机 处理器 中的 寄存器 ,它包含当前正在执行的指令的地址(位置)。
中文名: 程序计数器
外文名: Program Counter
外语简称: PC
* 导包
导包只可以导到当前层,不可以再导入包里面的包中的类
java.awt.*是导入java\awt包下所有的类,并不包括其子包下的类。
java.awt.event.*才能导入java\awt\event包下的类。
* 二维数组命名
二维数组中第一个中括号中必须要有值,它代表的是在该二维数组中有多少个一维数组。

注意: float []f[] = new float[6][6]; //这个变量声明方式是对的!
* 实例对象也可以调用静态方法。(可以通过编译,但是不建议这样用)
static表示类方法,在类加载的时候就完成了,而那时对象还没创建完成,就不能用this
* 类指外部类的访问修饰符
- 修饰符有public(表示该类在项目所有类中可以被导入)
- default(该类只能在同一个package中使用)
- abstract
- final
总结:
外部类:public 默认 Java外部类不能用private和protected修饰
成员内部类:内部类理解成类的成员,成员有4种访问权限吧,内部类也是
* interface 修饰符
写酱紫的源代码

* 值传递 i= i ++;
int i = 0;
i= i ++;
System.out.println(i); //0梅开二度:
链接:https://www.nowcoder.com/questionTerminal/5ce602538d784f51a531bf9760592773 来源:牛客网
for循环外面count=0,循环里面的count=count++;(count的值都等于count值,而后面count自加不影响count结果,因此这个式子无意义);循环count都为0(因count++是先返回count的本身值再自加1的)!而加1的这个temp又没有赋值给别人所以没用上!
count0=count1++的执行步骤: tmp=count1; count1++; count0=tmp;
若是改为count=++count;(先自加,再返回自加后的值),结果就是5050101=510050了!
改为count++;结果就是5050*101=510050了!
* switch语句中的参数
链接:https://www.nowcoder.com/questionTerminal/70bab9b529ec42ebafd850cd5877dcdd 来源:牛客网
以java8为准,switch支持10种类型
基本类型:byte char short int
对于包装类 :Byte,Short,Character,Integer String enum
2、实际只支持int类型 Java实际只能支持int类型的switch语句,那其他的类型时如何支持的
- a、基本类型byte char short
- 原因:这些基本数字类型可自动向上转为int, 实际还是用的int。
- b、基本类型包装类Byte,Short,Character,Integer
- 原因:java的自动拆箱机制 可看这些对象自动转为基本类型
- c、String 类型
- 原因:实际switch比较的string.hashCode值,它是一个int类型 如何实现的,网上例子很多。此处不表。
- d、enum类型
- 原因 :实际比较的是enum的ordinal值(表示枚举值的顺序),它也是一个int类型 所以也可以说 switch语句只支持int类型
* 二分
Java 中的 Arrays 类提供了一个 binarySearch 方法,用于在已排序的数组中进行二分查找。
* Map 通过匿名内部类方式初始化会有内存泄漏问题
* ConcurrentHashMap 1.7 vs 1.8
jdk1.7 数组+链表,分段锁内部类 class Segment<K,V> extends ReentrantLock
- 锁粒度包含多个节点 Hash
Entry
jdk1.8 数组+链表+红黑树,CAS+Synchronized
锁粒度锁单节点
Node使用内選锁 Synchronized 代替重入锁 ReentrantLock, Synchronized 是官方一直在不断优化的,现在
性能已经比较可观,也是官方推荐使用的加锁方式。
* 并发和并行有什么区别?
并发:两个或多个事件在同一时间间隔发生。
并行:两个或者多个事件在同一时刻发生。
并行是真正意义上,同一时刻做多件事情,而并发在同一时刻只会做一件事件,只是可以将时间切碎,交替做多件事情。
网上有个例子挺形象的:
你吃饭吃到一半,电话来了,你一直到吃完了以后才去接,这就说明你不支持并发也不支持并行。
你吃饭吃到一半,电话来了,你停了下来接了电话,接完后继续吃饭,这说明你支持并发。
你吃饭吃到一半,电话来了,你一边打电话一边吃饭,这说明你支持并行。
* 线程状态

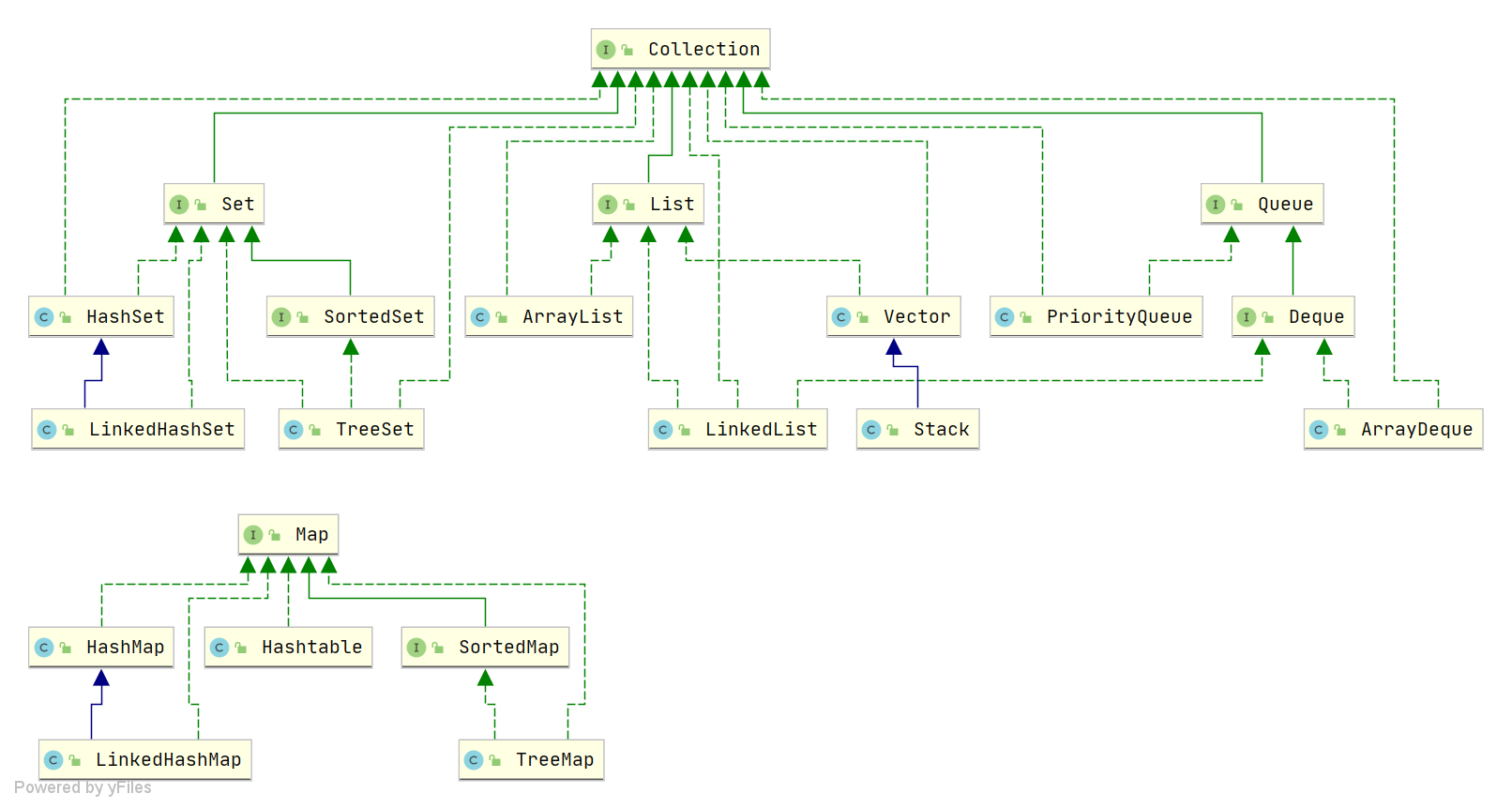
* Java集合
java中ArrayDeque和Stack类哪个用来实现栈方便一些
ArrayDeque更加方便实现栈,它具有更好的性能、更多的功能和更好的代码风格。因此,在实际开发中,推荐使用ArrayDeque来实现栈的功能。Stack是较早版本的类
* 谈一谈你对面向对象的理解
面向过程让计算机有步骤地顺序做一件事,是过程化思维,使用面向过程语言开发大型项目,软件复用和维护存在很大问题,模块之间耦合严重。
面向对象相对面向过程更适合解决规模较大的问题,可以拆解问题复杂度,对现实事物进行抽象并映射为开发对象,更接近人的思维。
例如开门这个动作,面向过程是 open(Door door),动宾结构,door 作为操作对象的参数传入方法,方法内定义开门的具体步骤。面向对象的方式首先会定义一个类 Door,抽象出门的属性(如尺寸、颜色)和行为(如open 和 close),主谓结构。
面向过程代码松散,强调流程化解决问题。面向对象代码强调高内聚、低耦合,先抽象模型定义共性行为,再解决实际问题
* 类加载具体过程?
类加载是Java虚拟机(JVM)将类的字节码加载到内存中并转换为可执行的Java类的过程。类加载过程包括以下几个步骤:
- 加载(Loading):通过类的全限定名(Fully Qualified Name),获取类的字节码数据。字节码可以来自文件、网络、数据库等各种来源。
- 验证(Verification):对字节码进行验证,确保其符合Java虚拟机规范。验证过程包括文件格式验证、元数据验证、字节码验证、符号引用验证等。
- 准备(Preparation):为类的静态变量分配内存空间,并设置默认初始值。不包括实例变量,实例变量的准备是在对象实例化时进行的。
- 解析(Resolution):将类、接口、字段和方法的符号引用转换为直接引用。符号引用包括类或接口的全限定名、字段或方法的名称和描述符等。
- 换句话说,符号引用是一种符号化的表示方式,用于描述类、接口、字段或方法的名称和类型等信息,而直接引用是一种具体的内存地址,用于直接访问类、接口、字段或方法在内存中的实际数据。
- 将字节码文件转换为机器码是在Java虚拟机执行类加载过程中的解析和执行阶段进行的。具体来说,这一步骤是在解析阶段进行的
- 初始化(Initialization):执行类的初始化代码,包括静态变量的赋值和静态代码块的执行。在这个阶段,会执行类中的静态初始化器(Static Initializer)。
- 使用(Usage):类加载完成后,可以通过创建对象、调用方法等方式使用该类。
需要注意的是,类的加载是按需进行的,即在使用到类时才会进行加载。另外,类加载过程是由Java虚拟机的类加载器(ClassLoader)负责执行的。Java虚拟机提供了三种内建的类加载器:启动类加载器(Bootstrap Class Loader)、扩展类加载器(Extension Class Loader)和应用程序类加载器(Application Class Loader)
类加载器具体看 JVM.md
#重载和重写
首先他们都是实现多态的方式
然后说一下他们基本的概念
不同点:
重载是编译时多态性,重写是运行时多态性
重载发生在一个类中,重写发生在子类和父类之间
重载不要求返回类型,重写要求返回类型相同
注意点:重写的返回类型不要求完全一样 - 返回类型使用父类的子类
已下这两个不构成重载:
public void getSum(int i,int j)
public int getSum(int i,int j)
#讲一下 HashMap 的哈希函数怎么实现
(h = key.hashCode())^ (h >>> 16),首先调用 hashCode() 方法对 key 求 hash值,然后将hash值的低 16 位bit和高 16 位 bit 做异或运算获得 新的 hash 值,然后 (n - 1) & hash 获得下标 (n 指数组的长度)
为什么要和高16位进行 ^ 运算?
- 哈希桶的选择是通过对哈希码进行进一步的运算转换得到的。HashMap使用哈希码的高位和低位进行异或运算,以获得一个更均匀的分布。
- 运算的目的是将哈希码的高位和低位的信息结合起来,使得哈希码的分布更加均匀,减少哈希冲突的概率,并提高查找的效率。
为什么 & 位必须是(length - 1)?
长度是2的幂次,length -1 的所有二进制都是1,相当于 取余数,但是比 % 运算更快, table[i = (n -1)& hash];
XD: 这个可以看Chrome书签 因为 2^n 满足 & 条件
为什么用 ^ 而不是用 & 或 |
因为 & 和 | 都会使结果偏向 0 或者 1,并不是均匀的概念,所以用 ^
#然后讲一下 hashmap 线程并发安全问题
多个线程同时 put , 当 put 的 key 一样造成一个线程 put 的数据被覆盖
多个线程同时检测到元素个数超过数组大小 * loadFactor, 同时对Node 数组 进行扩容,都重新计算元素位置和复制数据,最终只有一个线程扩容后的数据会复制成功,其他线程丢失,并且 put 的数据也丢失。
链表和红黑树转换的时候会抛出类型转化异常:两个线程同时将红黑树转换成链表,一个线程转换成功,红黑树变成链表了,另一个线程开始转换就会发现红黑树变成了链表,就会抛出类型转化异常。
#说一下java对象中的对象拷贝?
浅拷贝:拷贝对象时,对基本数据类型进行拷贝,而引用数据类型只进行了引用地址的传递,没有创建新对象
深拷贝:引用数据类型拷贝创建了新的对象,并复制其内的成员变量
ps: clone() 是浅拷贝
如何进行深拷贝:
方法一:
- 对应的引用类型class也实现了cloneable接口
- 对当前对象 clone(),对其内部的
引用类型再一次clone()
public class User implements Cloneable {
private String name;
private Address address;
// constructors, getters and setters
@Override
public User clone() throws CloneNotSupportedException {
User user = (User) super.clone();
user.setAddress(this.address.clone());
return user;
}
}
//name 不可变性所以没关系,original的改变不会影响deepCopy方法二:
序列化这个对象,再反序列化回来就是一个新对象
Java基本语法
一、基础类型
容量小->容量大:
byte、short、char、< int < long < float < double
难点:
1. float表示的范围比long大原因是,float与long在内存中的存储方式不一样。
2. 至于为什么 Java 中 char无论中英文数字都占用2字节,是因为 Java 中使用 Unicode 字符,所有字符均以2个字节存储。 而如果需要识别字符是否为中文,可以使用正则匹配式。
3. char c = ''; //编译不通过
4. char + int = int3.之所以不通过:String底层char[]数组长度为0个,而这里是1个char 所以必须指定内容
String可以和boolean拼接
注意:char对应一个ASCII码两个char相加就是ASCII码相加
short s = 5; s = s-2;//不能通过编译,因为2是int,所以要用int接收
计算机底层都以补码的方式来存储数据,运算的(关注负数就行,因为正数补码是本身)!
原码才可以对应为正常的整数,补码只有转换为原码才能被正常人类识别。(~...)
int a = 12,b = 5;
double c = a / b;
double d = a / (b+0.0);
System.out.println(c+"\t"+d); //2.0 2.4
注意这个2.0!!! short s1 = 10;
s1 ++;//自增1不会改变本身变量的数据类型&|这两个符号既可以是逻辑运算符又可以是位运算符,取决于它的运算类型
【面试题】 你能否写出最高效的2 * 8的实现方式? 答案: 2<<3或8<<1
注意:位运算符操作的都是整型的数据
强转要带括号:(char)(ans01-10+'A') 前面这个char要用括号包起来
题目: 如何求一个0-255范围内的整数的十六进制值,例如60
//要求手动实现 十六进制表示形式3C.
//分析:0-255 8位所以只关注后面8位就行,且按规则每4位组一个数
//15的二进制数是1111 所以取这个数的后四位就是&15 这是关键***** 【每个十六进制位对应4个二进制位】
int n = 60;
int ans01 = n & 15;
String s1 = ans01 > 9 ? (char)(ans01-10+'A')+"" : ans01+"";
ans01= n >>> 4 & 15;
String s2 = ans01 > 9 ? (char)(ans01-10+'A')+"" : ans01+"";
System.out.println(s2+s1);//3C需掌握两个排序:
- 冒泡 O(n^2) 简单
- 快排 O(nlogn) 用的多
面向对象
以下是我不熟的知识点:
变量分为属性(成员变量) vs 局部变量
属性可以用权限修饰符,局部变量不能!
局部变量要先赋值再用,成员变量有默认的属性值
默认初始化值的情况:
属性:类的属性,根据其类型,都有默认初始化值。
整型(byte、short、int、long):0
浮点型(float、double):0.0
字符型(char):0 (或'\u0000')
布尔型(boolean):false
引用数据类型(类、数组、接口):null 局部变量:没有默认初始化值。
意味着,我们在调用局部变量之前,一定要显式赋值。
特别地:形参在调用时,我们赋值即可。属性的赋值顺序:
1. 默认初始化
2. 显示初始化/代码块
3. 构造器
4. 对象.属性 对象.方法在内存中加载的位置:
属性:加载到堆空间中 (非static)
局部变量:加载到栈空间抽象、接口(自己的理解):
共同点:1)不能实例化 2)可包含抽象方法 3)都可以由默认实现 default
不同点:
语法方面 1)单继承多实现 2)接口成员变量只能 public static final
设计方面 1)接口用于对类的行为进行约束,抽象类用于代码复用强调所属关系【接口是“有没有”,集成是“是不是”】 2)接口是一种行为规范,辐射式设计,有没有,是一种自顶向下的设计。抽象类是一种模板式设计,是自底向上的。
抽象和接口用到多态,因为它们不能实例化(new)。
例如:Employee x = new Manager();
既然不能new的话就通过多态,如上Employee这个抽象类就可以用属于自己的属性和方法。
一般多态体现在方法的形参上。一般形参申明为父类,实际传子类对象,这样父类和子类都可以穿。
注意抽象类是能继承非抽象类的(默认继承Object)
接口是多继承的!
接口不能定义构造器!抽象类可以!
接口属性默认:public static final
方法默认:public abstract
接口默认为public abstract,所以接口的修饰符可以为abstract
//XD 2023/12/13 接口中可以有static default方法
jdk8接口除了可以定义全局常量和抽象方法外,还可以定义静态方法和默认方法(这两个有方法体),如下:
注意默认还是public!!!
static void a() {
//接口中的静态方法只能接口来调,实现类是掉不了这个a方法的。 【不要想复杂了,就和平时一样静态方法属于类 这里属于接口】
//有点像工具类靠,换句话说接口越来越像类了例如Collection
}
default void b() {
}
!!!
有了对象的多态性以后,内存中实际上是加载了子类特有的属性和方法的,但是由于变量声明为父类类型,导致编译时,只能调用父类中声明的属性和方法。子类特有的属性和方法不能调用。如何才能调用子类特的属性和方法?使用向下转型。
- jdk1.8,接口是否可以实现default的方法
- 这块只记得可以,然后面试官讲了一下为什么可以,主要是为了在后续的开发中如果扩展接口的功能,同时还可以兼容以前的实现类。
XD 2023/12/26 补充:接口的default方法作用:
在 Java 8 之前,一旦一个接口被定义并被实现类实现,就无法在接口中添加新的方法,因为这将导致所有实现类都需要修改以实现新的方法。这对于已经发布并广泛使用的接口来说是一个严重的限制,因为它违背了面向对象设计中的开闭原则(Open-Closed Principle),即对扩展开放,对修改关闭。
通过引入接口的默认方法,可以在接口中添加新的方法并提供默认实现,这样现有的实现类可以继续使用默认实现,而不需要对它们进行修改。如果实现类需要覆盖默认方法,它们可以选择重写默认方法以提供自定义的实现。这种方式保证了现有的实现类与新版本的接口兼容,同时还允许实现类选择性地适应新的接口功能。
匿名对象(自己的理解):
目的:图省事,只用一次。可以lambda开闭原则(对扩展开放,对修改封闭)
因为Integer作为常量时,对于-128到127之间的数,会进行缓存,也就是说int a1 = 127时,在范围之内,这个时候就存放在缓存中,当再创建a2时,java发现缓存中存在127这个数了,就直接取出来赋值给a2,所以a1 == a2的。当超过范围就是new Integer()来new一个对象了,所以a、b都是new Integer(128)出来的变量,所以它们不等。
首先这是JDK在1.5版本中添加的一项新特性,把-128~127的数字缓存起来了,用于提升性能和节省内存。所以这个范围内的自动装箱(相当于调用valueOf(int i)方法)的数字都会从缓存中获取,返回同一个数字,所以现在你理解为什么了吧。同时这也会给我们开发带来预想不到的陷阱,直得注意!!
后来:
* Integer i = 10 等价于 Integer i = Integer.value0f(10) ###装箱
* int n = i 等价于 int n = i.intValue(); ###拆箱
基本数据类型不能拥有面向对象的好处,包装类可以。。。
1)基本数据类型都有默认值,而包装类可以是 null 更加符合业务!!!
2)包装类型可用于泛型,而基本类型不可以
对Integer的缓存,我们在日常开发时,对于小的整型值应该充分利用Integer的缓存对象省去过多的对象创建,回收的操作,这样会极大的提高程序性能笔试题
interface A {
int x = 0;
}
class B {
int x = 1;
}
class C {
public static void main(String[] args) {
System.out.println(super(x));
System.out.println(A.x);//要记得接口的属性默认为:public static final
}
}
------------------------以上error-------------------------
//下面才是正确的写法,注意super!!!(super是指向父类的引用)
interface A {
int x = 0;
}
class B {
int x = 1;
}
class Solution extends B implements A {
public void pX() {
System.out.println(super.x);
System.out.println(A.x);
}
public static void main(String[] args) {
new Solution().pX();
}
}内部类:
person中有brain(大脑)如果我放外面那就和person平级了别的地方又用不到,但是brain用String这种又差点意思,所有有了内部类。
内部类:成员内部类 vs 局部内部类
一般看源码会出现,实际开发少。异常:
补充:IOException 是 Java 中的一个受检异常(checked exception),这意味着在编译时编译器会强制要求对其进行处理或声明。 XD: 后来补充-SQLException也是(checked exception)
搞清楚 checked exception 是必须要 try-catch 的不然报错不准运行!
要写出常见的异常
try/catch try抛出 发现这条语句有异常,跳对应的catch中处理,那条有异常的语句后面的代码就不会再执行了!!! catch处理完后继续往下运行。
注意catch一般都是细致的异常写前面,大的写后面(Exception)
编译时的异常用try/catch包起来就不会爆红了,但运行时依旧是错的,相当于把编译时的可能出现的异常,延迟到运行时出现。
为什么需要finally:因为像数据库连接,IO流,socket网络编程等资源JVM是无法自动回收的,我们需要手动进行资源释放,所以要放finally(finally是无论是否发生异常代码总会执行的!)
自己后面补充(不知道对不对) ---> 关闭资源为什么不写到catch里面:因为catch里如果又发生异常了又会产生一样的场景
一般try/catch/finally是针对编译时异常使用。
要保证资源的关闭,所以不能用throws
在每一个可能返回(return)的地方,以及每一个可能出现异常而导致程序跳转的地方,程序员不得不考虑如何释放资源,导致复杂和冗余。所以,需要finally语句。把资源释放或状态还原的代码放到finally块中,可以保证在try和catch语句执行完后,一定会执行finally语句块,而不用考虑各种复杂的跳转情况。
//代码1
public static void test() throws Exception {
throw new Exception("参数越界");
System.out.println("异常后"); //编译错误,「无法访问的语句,不可达代码」
}
//代码2
try{
throw new Exception("参数越界");
}catch(Exception e) {
e.printStackTrace();
}
System.out.println("异常后");//可以执行
//代码3
if(true) {
throw new Exception("参数越界");
}
System.out.println("异常后"); //抛出异常,不会执行
可以自定义异常类:三步,模仿API的异常类
1、继承Exception/RuntimeException
2、序列化
3、调构造方法super()一些小点:
位运算 是公认的 高效运算,在高频计算中,可以使用位运算替换一般简单的乘除法来提升系统性能。
位运算比直接的乘除法 在效率上 提升了 不止一个数量级,这是非常可观的。Java高级部分
多线程
自己的理解:
程序:一段静态代码
进程:程序放内存中跑起来运行了
线程:比如360可以杀毒,清理垃圾等同时进行
一个java程序跑起来至少有3个线程:1. main 主线程
2. GC垃圾回收线程
3. 异常处理线程
跑一个线程有4步:1. 写一个类继承Thread
2. 重写Thread的run方法(放自己的业务代码)
3. new出自己写的那个类(Thread类的子类对象)
4. 调这个对象的start()方法:注意不是run()
如果线程只用一次可以考虑用Thread类的匿名子类的方式:
new Thread(
()-> System.out.print();
).start();
关于同步方法的总结:1. 不需要显示声明同步监视器
2. 非静态同步方法,同步监视器是--->this
3. 静态同步方法,同步监视器是--->当前类本身
yield()
join():在线程a中调用线程b的join(),此时线程a就会进入阻塞状态,直到线程a等线程b全部执行完,结束阻塞状态。
线程的优先级:默认是5,最大是10,最小是1 ------> 概率
创造多线程的方式二: 实现Runnable接口 ------> 具体看api文档,有模板
------> 开发时优先选择 1. 没有类的单继承局限
2. 更适合处理多个线程有共享数据的情况
wait() notify() notifyAll() 是定义在java.lang.Object类中
sleep()和wait()的异同:
1. sleep()在Thread类中,wait()在Object中
2. sleep()不会释放同步监视器(锁),wait()会释放同步监视器。
3. wait()必须在同步代码块中使用,sleep()可以在任何场景。
实现线程有四种方式:
jdk 5.0加了一个实现callable接口,相对于Runnable的优势:
1. 相比run()方法,可以有返回值
2. 方法可以抛出异常(run()只能try catch)
3. 支持泛型的返回值
4. 需要借助FutureTask类
还有一种线程池ps:多线程只是草率的过了一遍,大概了解了里面的东西,但是没有跟着敲代码,对多线程的很多点理解的并不深刻。
java常用类
String 1. final,不可被继承,不可变性!(这个在值传递问题考的多!)
2. 实现了serializable接口,表示字符串是支持序列化的(IO流部分)
3. 实现了comparable接口,表示String可以比较大小。
注意:People p1 = new People("Tom",1);
People p2 = new People("Tom",2);
p1.name == p2.name; //true
//因为上面都是以字面量的形式赋值Tom,所以都是指向字符串常量池中的Tom面试题:String s1 = new String("abc"); 在内存中创建了几个对象?答:两个:一个堆空间new的,一个char[]对应的常量池中对应的数据"abc"
有空多看看源码
String对象的创建:
String s1 = new String();
//本质上 this.value = new char[0];
1. 常量和常量拼接结果在常量池,且常量池不会存在相同内容的常量。
2. 只要有一个是变量,结果就在堆中(实际内容再从常量池中引)
3. 如果拼接的结果调用intern()方法,返回值就在常量池中
String s1 = "javaEEhadoop";
String s2 = "javaEE";
String s3 = s2 + "hadoop"; //false
final String s4 = "javaEE";
String s5 = s4 + "hadoop"; //true
utf-8一个字符3个字节,gbk一个汉字2个字节。
byte[] bytes = str.getBytes();//使用默认的字符集进行编码
new String(bytes);//使用默认字符集进行解码
开发中推荐用StringBuffer(容量) //如果知道容量就给,避免反复扩容影响效率
//通过字面量定义的方式:此时的s1和s2的数据javaEE声明在方法区中的字符串常量池中。
String s1 = "javaEE";
String s2 = "javaEE";
//通过new + 构造器的方式:此时的s3和s4保存的地址值,是数据在堆空间中开辟空间以后对应的地址值。
String s3 = new String("javaEE");
String s4 = new String("javaEE");
//一道面试题 ------> String的不可变性
public class StringTest {
String str = new String("good");
char[] ch = { 't', 'e', 's', 't' };
public void change(String str, char ch[]) {
str = "test ok";
ch[0] = 'b';
}
public static void main(String[] args) {
StringTest ex = new StringTest();
ex.change(ex.str, ex.ch);
System.out.println(ex.str);//good
System.out.println(ex.ch);//best
}
}日期类型自己看api学,枚举注解也自己看博客学
注解
学 RuoYi 补充
我们一般知道,注解是给程序看的,给机器看的,当然也是给程序员看的。注解如果没有注解解析器(注解处理器,注解解释器),那么注解就没有什么作用。所以@Anonyous一定是在某个地方被干嘛干嘛了!
RuoYi 中注解一般头上加了 @Retention(RetentionPolicy.RUNTIME) 方便反射动态拿,然后再做一系列逻辑!
比如:@Log @Anonymous @RateLimiter 都是RuoYi自己写的然后再Services层再反射拿做一系列相应业务
对象比较器
comparable comparator 接口
首先实现comparable的类必须实现comparaTo(),然后就可以通过Arrays.sort或者Collectoins.sort进行自动排序集合
for(String a : arr) {
a = "hh";
}
注意:这里再重新遍历这个arr数组发现还是没变。
List 1.2 : 有序、可重复
ArrayList 1.2 ------> 线程不安全,效率高
避免扩容,在知道长度的情况下尽量调有参构造器把容量确定好
1.8的源码是在调用add()时才把数组创建好,不然一开始只是一个常量{}。。。这样的好处是延迟了数组的创建,节省内存。类似于单例的懒汉式。
1.7类似单例的饿汉式,一开始声明的时候就给你开辟一个大小为10的空间。
注意remove()有两个,一个是根据下表,一个是根据值
LinkedList 1.2 ------> 双向链表,适合频繁的插入、删除操作
Vector 1.0 ------> 出现的比上面的都早!和List作比较:线程安全,效率低
这个基本不用了,因为ArrayList可以通过工具类Collections的SynchronizedList转成一个线程安全的!!!
set : 无序、不可重复
如需像set添加数据,所在的类需要重写hashCode() equals()方法,不然都默认用的是Object类中的方法。。。注意重写这两个方法时要保证一致性。
HashSet(数组+链表) ------> 线程不安全
无序:不等同于随机性,在底层数组中并不是按照数组索引依次添加,而是按照数 据hash值决定的
不可重复(重要用的多):根据equals()判断
ps:假如自己设计一个set该如何设计,要保证不能重复就每添加一个元素就和数组里已有的元素equals,假如数组里有1000个元素,你加第1001个的时候就需要equals1000下这样显然效率太低了。所以有通过hash来实现这样的操作。先根据hashcode的某种算法找在数组的位置,如果该位置没有元素就直接添加到这,如果有元素了就equals比较true就证明一样,添加失败,全比完全false就证明没有一样的就可以添加,就加在链表的最后
LinkedHashSet ------> 可以按照添加的顺序遍历
在添加数据时还维护了两个引用,记录前一个数据和后一个数据。好处:对于频繁的遍历操作,效率要高于HashSet
TreeSet ------> 可以按照添加的对象的指定属性进行排序,底层是红黑树
要求添加的数据都是相同类的对象,如果加int就所有元素都得是int
比较两个对象是否相同的标准:ComparaTo返回0 不再是 equals
Map: 存的是Map.Entry<K,V> Map源码看着还是很痛苦,有时间再回过头看视频
HashMap ------> 1. 线程不安全
2. key,vlue可以存null值
3. 1.7: 数组+链表 1.8: 数组+链表+红黑树
4. 所有的key用set存 key所在的类要重写hashCode() equals()
5. Entry也是用set存
6. jdk7 的底层实现和HashSet有点像,先得到key的hashCode()再通过某种算法得到在Entry数组中的存放位置,再和这个位置上的元素比(见HashSet)区别就是比完发现key有一样的此时把现在这个key的value替换数组里以前的这个key对应的value
7. jdk8实现与7的区别:1. 底层数组是Node[] 而不是 Entry[],其实本质还是Entry
2. new的时候没有创建长度为16的数组,调用put()的时候才创建(和ArrayList一样)
3. 核心!!!当数组长度 > 64 且某一个索引位置以链表形式存在的数据个数 > 8时,此时索引位置上的所有数据改为使用红黑树存
LinkedHashMap ------> 对于频繁遍历操作,效率比hashMap高。可以按照添加顺序遍历
TreeMap ------> 对key进行排序(自然排序/定制排序) 底层红黑树
Hashtable ------> 古老 key/value不能存null
Properties ------> 常用来处理配置文件,框架!key/value都是String类型
哈希桶(数组的每个位置称为一个桶)补充:
- LinkedHashMap:需要记录访问顺序或插入顺序
- TreeMap:需要自定义排序
泛型
泛型的 <T> 必须是对象吗,基本数据类型可以吗
在Java中,泛型类型参数<T>必须是一个引用类型,而不是基本数据类型。也就是说,泛型类型参数必须是一个类或接口类型,或者是一个数组类型。
泛型常见的表示可以是<E> <T> <K,V> 也可以是自给随便给<E1,E2,E3,A,B,C>都行
T[] arr = new T[10]; // 编译不通过 因为T只是类型,不是类!
T[] arr = (T[]) new Object[10]; //编译通过
泛型方法:在方法中出现了泛型结构,泛型参数与类的泛型参数没有任何关系比如类是<E> 泛型方法是<T> 换句话说,泛型方法所属的类是不是泛型类都没有关系
public <E> List<E> copyFromArrayToList(E[] arr) //注意public后面的<E> 不加会编译报错,会看成是不是有个类叫E。。。。。所以要表示一下前面加<E>
通配符:
List<String> a 不能赋值给 List<Object> b
解决途径:通配符 ? List<?> c c = a; //ok c = b //ok 但对于c就不能向里添加数据了,除了添加null之外(因为所有类类型都可以赋值为null)
总结:类A是类B的父类,G<A>和G<B>是没有任何关系的,二者共同的父类是:G<?>
有限制条件的通配符使用:
List<? extends Person> l1 = null; //extends ---> <=
List<Person> List<student> 可以赋值给l1 List<Object>不行
List<? super Person> l1 = null; //super ---> >=
List<Person> List<Object> 可以赋值给l1 List<student>不行
可以这样理解:?(-∞,+∞) extends ---> (-∞,A]
super ---> [A,+∞)
写数据时注意,对于l1来说,不能把add(new Student) //因为不清楚是不是还有比Student小的类,拿上面数学的方式理解,因为负无穷大,假如有比Student小的子类,我不能把Student赋给这个子类。(向下强转,向上自然转)IO流
File类的一个对象:代表一个文件或文件目录
注意路径:windows是'\' linux和url是'/'
输入流 vs 输出流 : 注意看站位:我站位内存的位置,就是进内存的为输入,出内存的为输出
字符流 vs 字节流 : 字符流处理文本,其他像图片、视频什么的都是字节流
节点流 vs 处理流 :节点流是直接怼到数据的(可以理解为最原始的那根管道),处理流是作用在已有流的基础之上的(相当于管道外面再包一层)
关流:先关外层的再关内层的,关外层流时,内层流会自动关闭,所以关于内层流的关闭可以省略。
题目 : 实现图片加密操作(提示:异或) a^b^b = a a^5^5 = a
统计文本中每个字符出现的次数
处理流之二 : 转换流(属于字符流),提供字符流和字节流之间的转换
字符集:见视频p602,ANSI是平台默认编码,例如中文操作系统编码是GBK,英文操作系统是ISO-8859-1
对象流:
序列化:把对象存到数据源 ---> 允许把内存中的java对象转换成与平台无关的二进制流,允许把这种二进制流存到磁盘中,或通过网络传输
反序列化:把对象从数据源拿到内存 ---> 当其他程序获取到这种二进制流,可以把它恢复成原来的java对象
前台后台如果想传对象,就得要求这个对象是可序列化的
序列化需要加常量id,不加会有以下情况,假如person类,我序列化完成后再回过头会把person类给改动了,多加了一个id属性。这时我再反序列化是会报错的。
注意:可序列化类中所有属性要是可序列化的(基本数据类型和String默认是可序列化的)
static/transient修饰的属性不能序列化,也就是说序列化的时候明明给值了比如String我给了值但是在反序列化的时候没值是null(序列化保存的是对象的状态,静态变量属于类的状态,因此,序列化并不保存静态变量。)
不过一般序列化传值很少传Person这种,一般都是json(字符串格式,默认是可序列化的)
序列化保存的是对象的状态,静态变量属于类的状态,因此,序列化并不保存静态变量。网络编程
ip和端口号 and 网络通信协议
ip 定位到主机
端口号 定位正在运行的进程(程序)
网络协议太复杂 ---> 分层 OSI参考模型(7层,理想化)实施有困难,落地:TCP/IP参考模型(4层) 两台机器数据的传输 就相当于一台经过这4层一层层数据封装,拿数据的那一台就一层层的数据拆封
本地回环地址指的是以127开头的地址(127.0.0.1 - 127.255.255.254),通常用127.0.0.1来表示。
内网IP一般是私有IP通常有一下3种:
10.x.x.x
172.16.x.x---172.31.x.x
192.168.x.x
假如回到十几年前就别买房子了太贵了,买域名
InetAddress类
Socket = ip + 端口号
网络通信通常也叫Socket编程
UDP适合播放视频,丢几帧无所谓,但别给我卡在那
更好的生活例子:TCP(1.可靠,2.可大数据量传输,3.需释放已建立的连接,效率低):打电话
TCP三次握手四次挥手
UDP(1.不需要建立连接,2.每个数据包大小限制在64K内,3.无需释放资源,开销小,速度快):发短信,发电报
TCP --->
客户端:Socket
服务端:ServerSocket
注意一个类:ByteArrayInputStream包含一个内部缓冲区,其中包含可以从流中读取的字节 ---> 好处:假如取的时候原先传过来的时候有中文一个中文3个字节,可能有乱码。而这个类会把取到的缓存起来最后再一次性拿出来。就不会有一个中文劈成两半的情况。
需先启动服务器端,等待客户端访问
如先启动客户端握手会报错,连接失败
而UDP只管发,先启动谁都不会报错
UDP ---> 以数据报形式发送
发送端:
接收端:
TCP/IP参考模型 --->
应用层(HTTP,FTP,Telent,DNS...)
传输层(TCP,UDP...)
网络层(IP,ICMP,ARP...)
物理+数据链路层(Link)java反射机制
ps: 有难度,但又比较重要。要求代码先要会写,反射机制被视为动态语言的关键。
动态语言:在运行时代码可以根据某些条件改变自身结构。 java不是动态语言,但java可以称为准动态语言
重点:1.获取Class实例 2.创造运行时类对象(newInstance()) 3.调用运行时类的指定结构(指定结构中重中之重是方法)
特征:动态性
某种意义上 框架 = 反射 + 注解 + 设计模式
Class类是用来描述class类的类
具体看java.lang中的Class类和java.lang.reflect
反射的应用场景:编译时确定不下来造哪个对象
程序在服务器中已经运行起来了,如用户想注册(register)/登录(login)。这时通过反射服务器中运行的代码就会通过判断动态的创造相应的对象
关于java.lang.Class类的理解
1.类的加载过程:
程序经过javac.exe命令以后,会生成一个或多个字节码文件(.class结尾)。
接着我们使用java.exe命令对某个字节码文件进行解释运行。相当于将某个字节码文件
加载到内存中。此过程就称为类的加载。加载到内存中的类,我们就称为运行时类,此
运行时类,就作为Class的一个实例。
2.换句话说,Class的实例就对应着一个运行时类。
3.加载到内存中的运行时类,会缓存一定的时间。在此时间之内,我们可以通过不同的方式
来获取此运行时类。
1)获取Class实例:
//方式一:调用运行时类的属性:.class 编译时就写死了,没有体现动态性
//通过 类名.class 获取到字节码文件对象(任意数据类型都具备一个class静态属性)
Class clazz1 = Person.class;
//Class clazz = hello.class; //如果我没创hello会报这样的错:hello 无法解析为类型(hello不是类、接口、枚举、注解、数组、基本数据类型、void)
System.out.println(clazz1);
//方式二:通过运行时类的对象,调用getClass()
Person p1 = new Person();
Class clazz2 = p1.getClass();
System.out.println(clazz2);
//方式三:调用Class的静态方法:forName(String classPath)
//用的最多,也更好体现运行时的动态性,像第一种定死了,这种里面是个String只有运行时才会去判断有没有错找不不找得到
Class clazz3 = Class.forName("com.atguigu.java.Person");
// clazz3 = Class.forName("java.lang.String");
System.out.println(clazz3);
//方式四:ClassLoader 了解 类加载器的作用就是把类(cllas)装载进内存中 具体到JVM学类加载器,有三个
2)创建对象(基于上一步)
//方式一:直接Class对象API newInstance()
// 获取Class对象
Class<?> clazz = MyClass.class;
// 创建对象
Object obj = clazz.newInstance();
//方式二:通过Class对象获取构造对象,调用构造对象同名方法 newInstance()
// 获取Class对象
Class<?> clazz = MyClass.class;
// 获取构造函数
Constructor<?> constructor = clazz.getConstructor(String.class, int.class);
// 创建对象
Object obj = constructor.newInstance("example", 123);
需要学习JVM
// m = 0 m = 300 finally:m = 100
class A {
static {
m = 300;
}
static int m = 100;
}
// m = 300
class A {
static int m = 100;
static {
m = 300;
}
}
在javabean中要求提供一个public的空参构造器。原因:
1.便于通过反射,创建运行时类的对象
2.便于子类继承此运行时类时,默认调用super()时,保证父类有此构造器
有些东西封装好了直接用就好了,像api像后面导入的第三方开源jar包。就像以后自己有孩子了不可能学语言让他从甲骨文开始,人的精力有限,不要过于深究。知道这个干这个用的就好。学习的思维方式:
- “大处着眼,小处着手的意思是比喻既要从全局和长远的观点出发去考虑问题,也要在具体事情上一件件地做好,意为从大的目标去观察,从小的地方去动手。
- 逆向思维、反证法
- 透过问题看本质
两句话:
- 小不忍则乱大谋
- 识时务者为俊杰
反射的应用:动态代理
动态代理的优点是它可以在运行时创建代理对象,而不需要在编译时指定代理类
Spring: IOC容器(依赖注入) AOP(动态代理)
懂反射更好的理解框架的地层实现
代理模式
代理模式的作用是:为其他对象提供一种代理以控制对这个对象的访问。在某些情况下,一个客户不想或者不能直接引用另一个对象,而代理对象可以在客户端和目标对象之间起到中介的作用。
代理模式一般涉及到的角色有:
抽象角色:声明真实对象和代理对象的共同接口;
代理角色:代理对象角色内部含有对真实对象的引用,从而可以操作真实对象,同时代理对象提供与真实对象相同的接口以便在任何时刻都能代替真实对象。同时,代理对象可以在执行真实对象操作时,附加其他的操作,相当于对真实对象进行封装。
真实角色:代理角色所代表的真实对象,是我们最终要引用的对象。
多敲代码才能理解
静态代理例子:
class MyThread implements Runnable{} //被代理类
class Thread implements Runnable{} //代理类
main() {
MyThread t = new MyThread();
Thread thread = new Thread(t);
thread.start(); //启动线程,调用线程的run()
}java bin jjs.exe可以执行js文件,也就是说可以在jvm上运行js
Lambda表达式
ps: 具体看Lambda表达式.md文件
* java内置的4大核心函数式接口
*
* 消费型接口 Consumer<T> void accept(T t)
* 供给型接口 Supplier<T> T get()
* 函数型接口 Function<T,R> R apply(T t)
* 断定型接口 Predicate<T> boolean test(T t)
方法引用:
Consumer中的void accept(T t)
PrintStream中的void println(T t)
发现这两个刚好匹配上了(返回值,形参个数类型都一样)
又 System.out的类型为PrintStream (PrintStream ps = System.out;)
则可以 System.out::printlnStream API
ps: java8两个重要的改变,一个是Lambda另一个就是Stream API
stream流和for的区别?
stream流可以看作是for循环的一个语法糖;
stream有并发流,在超过百万级数据量时,使用stream流效率更高;
Stream API可以对集合数据进行操作,就类似SQL执行数据库查询
像mysql这种关系型数据库,一些过滤操作之类的都可以用sql语句实现,实现完后给java。
但是MongDB,Radis等,这种NoSQL的数据就需要到java层面处理过滤,这时用Stream API
Collection关注的是数据的存储,跟内存打交道
Stream关注的数据的运算,跟CPU打交道
方式一:
针对集合 Collection中两个default方法:
stream() 顺序流
parallelStream() 并行流:并行操作
方式二:
针对数组需要用Arrays有静态方法
方式三:
Stream of()
方式四:创建无限流(了解)
//迭代
// public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f)
//遍历前10个偶数
Stream.iterate(0, t -> t + 2).limit(10).forEach(System.out::println);
//生成
// public static<T> Stream<T> generate(Supplier<T> s)
Stream.generate(Math::random).limit(10).forEach(System.out::println);
map()映射就像hashMap根据K,V映射,这个方法可以根据你给定的规则映射
Reduce()规约例如把映射的信息做一个sum,计算1-10的自然数的和可以用这个
Optional类可以避免空指针异Junit是自动化的测试,手动的输出会导致一直阻塞,也就是说junit不支持手动输入,否则会导致当前线程一直阻塞,转圈圈,所以test类不要用scanner那种控制台手动输入数据的方式,把数据直接写成形参,测试的时候直接写成参数测试吧;
JUnit总是为每个@Test方法创建一个测试类实例,所以必须要声明成public,也就是公共的,才能让junit给你创建,否则权限不够的.
为什么重写 equals() 时必须重写 hashCode() 方法?
在 Java 中,重写
equals()和hashCode()方法是因为它们在使用集合类(如HashMap、HashSet、Hashtable等)进行元素比较和存储时起着重要的作用。
集合Set添加某元素时,先调用hashCode()方法,定位到此元素实际存储位置,如果这个位置没有元素,说明是第一次存储;若此位置有对象存在,调用equals()进行比较,相等就舍弃此元素不存,不等则散列到其他地址。
上面的示例也说明了为什么equals()相等,则hashCode()必须相等,进而当重写了equals方法,也要对hashCode()方法进行重写。 https://blog.csdn.net/wo541075754/article/details/114994906
java从1.5开始改名5.0
class People {
People(String s) {
}
}
public class StudyTest extends People {
//此时这个类会报错
//没有为缺省构造函数定义隐式超构造函数 People()。必须定义显式构造函数
//必须加以下
StudyTest(String s) {
super(s);
}
}
以下是默认情况:
class People {
}
public class StudyTest extends People {
}
会默认的在StudyTest默认的构造函数中,默认调super()我这里char会搞错
package com.example.spring_boot;
/**
* @author XD
* 2020/8/10 23:06
**/
public class Example {
String str = "good";
char[] ch = {'a', 'b', 'c'};
int a = 1;
String b = "a";
public static void main(String[] args) {
Example ex = new Example();
ex.change(ex.str, ex.ch); //good and abc
System.out.println(ex.str + "and");
System.out.println(ex.ch);
ex.change2();
System.out.println(ex.a + " " + ex.b); //2,b
}
private void change2() {
a = 2;
b = "b";
}
private void change(String str, char[] ch) {
str = "test ok";
ch = new char[]{'g'};
// ch[0] = 'g';
}
}
看下面这个简单的例子:答案是1
public static void main(String[] args) {
int[] ary = new int[] {1,2,3,4,5};
change(ary);
System.out.println(ary[0]);
}
public static void change(int[] i) {
i = new int[] {6};
}进阶:源码
一、JDK7的HashMap头插法循环的问题
问题出现在:多线程情况下的扩容,单线程是没有问题的
自己能理解的::::::) 模拟出错:两个线程,A 要扩容的时候阻塞了,等 B 扩完后。A 醒了要扩的那个状态还保留在没扩之前的状态
XD:插入一个元素分两步 1)放值 newTable[i]=e; 2)改指针 e=next; 【看下图,先放头部再迁移改指针】
B(线程1 插入 B阻塞)A -> B(线程1 插入 A)B(线程2插入 B 后醒来继续改指针,此时发现head指针在 A 前面 B -> A -> B)

一、jdk1.7 HashMap头插法在多线程环境下链表成环的场景怎么形成
2024 再回顾彻底搞清:
核心:扩容完顺序会逆过来,一直没get到这个核心点。导致迷迷糊糊怎么也搞不明白
两个线程扩容传递的是两个新的table,原来是ABC,t扩容完成变成了CBA,此时t2接着迁移对象遍历原来ABC,遍历到C的时候发现C的next节点是B,这样一直循环,这才叫死循环头插法的锅,因为头插法打乱了链表的顺序,导致两个线程的数据结构不一致导致了bug。如果使用尾插法就没有这个bug。
PS:JDK提供的HashMap从来就不是给多线程用的,现在非要内卷到研究把一个线程不安全的类放在多线程下会有什么问题,就好比ArrayList也是线程不安全的,我非要问你在多线程下使用ArrayList(没有别的同步保障)会有什么问题。如果是从研究源码的角度来说勉强说得过去,如果要说 ArrayList有问题,那是不是撑得?而且1.8的HashMap也是线程不安全的,所以才推荐用 ConcurrentHashMap。

在多线程环境下,链表成环的场景通常是由于链表的插入、删除等操作没有进行同步处理导致的。以下是一种可能的场景:
- 假设有两个线程 A 和 B,它们同时在对同一个桶的链表进行操作。
- 初始状态下,链表为空。
- 线程 A 插入一个键值对到链表的头部,此时链表中只有一个元素。
- 线程 B 也插入一个键值对到链表的头部,此时链表中有两个元素,且线程 B 插入的元素成为链表的头部。
- 线程 A 继续执行,在没有进行同步的情况下,它会将链表的头部指针指向自己插入的元素,即将线程 B 插入的元素剔除出链表,此时链表中只有一个元素,并且它的下一个指针指向它自己,形成了一个环。
这种情况可能会导致链表的遍历进入死循环,从而导致程序出现异常或崩溃。因此,在多线程环境下,对链表的操作一定要进行同步处理,避免出现数据竞争的问题。
但是更新链表头指针时,由于它不知道链表头指针已经被线程A更新了,所以它会将链表头指针指向X节点,而不是新元素
XD:线程 A 没有感知到 B,所以 A 把 head 指向了自己的 1 号元素,此时 B 继续做 add 操作
初始状态:链表为空
--------------------
|
v
+---+
| |
+---+
线程 A 插入元素 1
--------------------
|
v
+---+ +---+
| 1 | -> | |
+---+ +---+
线程 B 插入元素 2
--------------------
|
v
+---+ +---+
| 2 | -> | 1 |
+---+ +---+
线程 A 将头部指针指向元素 1
--------------------
|
v
+---+
| 1 | ----> 环
+---+ | ^
| |
| |
| v
+---+
| 2 |
+---+看着一段终于明白了:1)重点多线程没同步 2)head指针的覆盖!!!
因为线程 B 在线程 A 之后向链表头部插入了元素 B,所以链表中的第一个元素是 B,它的下一个指针指向元素 A,即 B->A。而线程 A 在链表头部插入元素 A 时,因为链表头部指针 head 被线程 B 覆盖了,所以它并不知道链表头部已经有一个元素 B 存在。因此,线程 A 会将它自己插入的元素 A 的下一个指针指向原来的第一个元素 X,即 A->X,而元素 X 的下一个指针又指向元素 B,即 X->B。这样,就形成了一个链表 A->X->B->A,其中元素 A 的下一个指针指向了元素 B,使得链表成环。
在线程 B 向链表头部插入元素 B 之后,元素 B 成为了链表中的第一个元素,它的下一个指针指向元素 A,即 B->A。 而此时链表头部指针 head 已经被线程 B 修改为指向元素 B,所以线程 A 在插入元素 A 时,会将它的下一个指针指向原来的第一个元素 X,即 A->X。而元素 X 在此时就是链表中的第二个元素,它的下一个指针指向元素 B,即 X->B。因此,链表变为了 A->X->B。而由于元素 B 的下一个指针指向元素 A,而元素 A 的下一个指针又指向元素 X,最终形成了一个闭环的链表 A->X->B->A。
eDiary
《JVM规范》
虚拟机栈,即为平时提到的栈结构。我们将局部变量存储在栈结构中 堆,我们将new出来的结构(比如:数组、对象)加载在对空间中。补充:对象的属性(非static的)加载在堆空间中。 方法区:类的加载信息、常量池、静态域

!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!2-3 顺序
- 总结:属性赋值的先后顺序
- ① 默认初始化
- ② 显式初始化 / 代码块
- ③ 构造器中初始化
- ④ 通过"对象.方法" 或 "对象.属性"的方式,赋值
- 以上操作的先后顺序:① - ② - ③ - ④
成员变量(static为界的实例变量和静态变量【类变量】)如果没有显式指定初始值,则会进行默认赋值; 也就是 static 的成员变量也会被默认赋值
链接:https://www.nowcoder.com/questionTerminal/c2bfb1512dfa4a7eab773a5871a52402 来源:牛客网
1.首先,需要明白类的加载顺序。 构造方法的优先级一般比代码块低。
(1) 父类静态代码块(包括静态初始化块,静态属性,但不包括静态方法) (2) 子类静态代码块(包括静态初始化块,静态属性,但不包括静态方法 ) (3) 父类非静态代码块( 包括非静态初始化块,非静态属性 ) (4) 父类构造函数 (5) 子类非静态代码块 ( 包括非静态初始化块,非静态属性 ) (6) 子类构造函数 其中:类中静态块按照声明顺序执行,并且(1)和(2)不需要调用new类实例的时候就执行了(意思就是在类加载到方法区的时候执行的) 2.其次,需要理解子类覆盖父类方法的问题,也就是方法重写实现多态问题。 Base b = new Sub();它为多态的一种表现形式,声明是Base,实现是Sub类, 理解为 b 编译时表现为Base类特性,运行时表现为Sub类特性。 当子类覆盖了父类的方法后,意思是父类的方法已经被重写,题中 父类初始化调用的方法为子类实现的方法,子类实现的方法中调用的baseName为子类中的私有属性。 由1.可知,此时只执行到步骤4.,子类非静态代码块和初始化步骤还没有到,子类中的baseName还没有被初始化。所以此时 baseName为空。 所以为null。
不会初始化子类的几种
- 调用的是父类的static方法或者字段
- 调用的是父类的final方法或者字段
- 通过数组来引用
有了对象的多态性以后,我们在编译期,只能调用父类中声明的方法,但在运行期,我们实际执行的是子类重写父类的方法。
总结:编译,看左边;运行,看右边。
重点懒汉式和饿汉式手写!!!
自己的区分:饿汉式 一上来就给你new好, instance = new xxx(); 懒汉式 是你想要我再给你new,判断当前有没有没有就new,所以有线程安全问题
我们都知道,饿汉式单例是线程安全的,也就是不会初始化的时候创建出两个对象来,但是为什么呢? 首先定义一个饿汉式单例如下:
public class Singleton {
// 私有化构造方法,以防止外界使用该构造方法创建新的实例
private Singleton(){}
// 默认是public,访问可以直接通过Singleton.instance来访问
static Singleton instance = new Singleton();
之所以是线程安全的,是因为JVM在类加载的过程,保证了不会初始化多个static对象。
一个Java应用程序java.exe,其实至少三个线程:main()主线程,gc()垃圾回收线程,异常处理线程。当然如果发生异常,会影响主线程。
自动类型转换(只涉及7种基本数据类型)
结论:当容量小的数据类型的变量与容量大的数据类型的变量做运算时,结果自动提升为容量大的数据类型。 byte 、char 、short --> int --> long --> float --> double 特别的:当byte、char、short三种类型的变量做运算时,结果为int型 说明:此时的容量大小指的是,表示数的范围的大和小。比如:float容量要大于long的容量
HashMap
当数组的某一个索引位置上的元素以链表形式存在的数据个数 >= 8 且当前数组的长度 > 64时,此时此索引位置上的所数据改为使用红黑树存储。当红黑树的节点小于或等于 6 个以后,又会恢复为链表形态。
DEFAULT_INITIAL_CAPACITY : HashMap的默认容量,16 DEFAULT_LOAD_FACTOR:HashMap的默认加载因子:0.75 threshold:扩容的临界值,=容量*填充因子:16 * 0.75 => 12 TREEIFY_THRESHOLD:Bucket中链表长度大于该默认值,转化为红黑树:8 MIN_TREEIFY_CAPACITY:桶中的Node被树化时最小的hash表容量:64
注:自己的理解,上面的0.75可能是通过统计学的泊松分布算出来的0.7-0.75 然后选的0.75
在put()时初始化Node[]数组,长度为16,当数组中放了12个元素(扩容的临界值)了就要考虑扩容。放第13个的时候先看要放的位置是不是空的能不能放进去,能的话就放,不能的话就考虑扩容。
一定要区分:实例变量 vs 类变量

实例变量指的是类中定义的变量,即成员变量 注意:两者如果没有初始化,都会有默认值。
检查异常(编译器要求必须处置的异常)
除了Error,RuntimeException及其子类以外,其他的Exception类及其子类都属于可查异常。这种异常的特点是Java编译器会检查它,也就是说,当程序中可能出现这类异常,要么用try-catch语句捕获它,要么用throws子句声明抛出它,否则编译不会通过。
非运行时异常 总是在我们写的时候就会出错 提醒我们try catch 或throw (一般是 File、SQL 相关)
但是运行时异常检查不出来,只有运行时才会出错,所以也不需try catch (注意 ClassCastException)
Tomcat
* 本地访问 / Tomcat访问
Tomcat 包裹http+css+js静态包里面的其他文件 解决跨域问题不能访问
一个是 HTTP 协议,一个是 file 文件协议 【http:// file:///】
- 场景:为什么本地访问.js / .css文件却可以,唯独.json文件会报错
在本地访问
.js和.css文件而不报错的原因是因为这些文件通常被浏览器解释为纯文本文件或脚本文件,并且不需要通过特定的解析器来处理。而
.json文件是一种特殊的文件类型,被解释为 JSON(JavaScript Object Notation)格式的数据。JSON 是一种用于存储和交换数据的文本格式,它具有特定的语法和结构。当浏览器遇到.json文件时,会尝试将其解析为有效的 JSON 数据。由于安全和隐私的考虑,现代浏览器不允许直接从本地文件系统加载 JSON 文件,即使该文件位于你的计算机上。这是浏览器的安全策略之一,旨在防止网站通过访问本地文件系统来获取敏感信息。
当你通过 HTTP 协议从服务器加载
.json文件时,浏览器会遵循同源策略,并允许从同一个源加载该资源。这是因为浏览器认为服务器上的资源是安全的,且不会对用户的本地文件系统造成潜在的风险。为了在本地访问
.json文件而不报错,你可以将文件部署到一个本地服务器上,并通过 HTTP 协议进行访问,就像我之前提到的在本地运行时使用 Python 简单的 HTTP 服务器一样。这样可以避免浏览器的安全限制,并正常加载和解析 JSON 数据。请注意,在实际的生产环境中,你应该将 JSON 文件部署到一个正式的 Web 服务器上,并通过合适的 URL 来访问,而不是依赖本地文件系统路径。
- 换句话说本地只支持html+css+js,其他文件类型都访问不到吗
在本地环境中,浏览器通常支持加载和渲染多种文件类型,包括 HTML、CSS、JavaScript、图像文件(如JPEG、PNG)、字体文件(如TTF、WOFF)、音频文件(如MP3、WAV)、视频文件(如MP4、WebM)等。
对于大多数文件类型,浏览器在本地运行时都可以正常加载和呈现,无论是直接通过文件路径访问还是通过本地服务器进行访问。
然而,对于某些文件类型,浏览器在本地环境中可能会施加一些安全限制。例如,对于包含敏感数据的
.json文件,浏览器会限制直接从本地文件系统加载,以防止潜在的安全风险。这些安全限制在本地环境中是为了保护用户的安全和隐私而存在的。当你需要在本地加载特定文件类型时,可以考虑使用本地服务器来提供这些文件,或者调整浏览器的安全设置以允许加载特定文件类型。
需要注意的是,在实际的生产环境中,文件的加载和访问通常通过一个正式的 Web 服务器来进行,而不是依赖本地文件系统路径。这样可以确保文件的可靠性、安全性和可访问性,并遵循浏览器的安全策略和同源策略。
- .txt支持吗
是的,大多数浏览器在本地环境中支持加载和显示文本文件(.txt)。文本文件是一种纯文本格式,可以包含普通文本、代码、配置信息等。
Success:

Error:


其实像大屏那样处理就行,把 JSON 不要搞文件夹。直接粗暴放 JS 就行!!!
PS: 这样也可以显示地图,但是一般不这样写

Tomcat CORS 解决,不用自己写类
<filter>
<filter-name>CorsFilter</filter-name>
<filter-class>org.apache.catalina.filters.CorsFilter</filter-class>
<init-param>
<param-name>cors.allowed.origins</param-name>
<param-value>*</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>CorsFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>位运算
^ 相同为0,不同为1
异或是无进位加法!
- 任何数异或0都等于它本身
- 任何数异或本身都为0
- 1异或任何数都为任何数取反
&
&运算代替%,例如a&15 15后四位二进制为1前面全为0,得出来的数不会超过15
- 0&1=0 1&1=1 通常拿最后一个数&1取这一位的数